[논문번역] USAD: UnSupervised Anomaly Detection an Multivariate Time Series (KDD 2020)
시계열 데이터 이상치 탐지 모델
paper: https://dl.acm.org/doi/pdf/10.1145/3394486.3403392
code: https://github.com/manigalati/usad
시계열 데이터에서 이상치를 탐지하는 비지도 학습 방법.
Auto Encoder와 Adversarial Training을 같이 사용하는 것이 특징.
매우 간단한 구조를 가지고 있다.
Abstract
IT 작업에서 정상, 비정상을 구분하는 작업을 사람이 하는 것은 느리고 에러가 나올 수 있다.
세줄요약
- 적대적으로 학습된 오토인코더에 기반한 빠르고 안정적인 방법을 제안했다.
- 오토 인코더의 구조로 비지도 방법으로 학습을 진행할 수 있도록 한다.
- 다섯가지의 공공 데이터셋으로 이 모델의 robustness(굳건함), 빠른 학습속도, 높은 이상 탐지 증력을 증명했다.
Introduction
최근에 큰 관심을 받고 있는 anomaly detection에서의 딥러닝 기반의 방법은 GAN기반의 방법들이다. 하지만 GAN 학습은 mode collapse와 non-convergence와 같은 이유로 쉽지 않다.
이러한 방법들을 구현하고 제품으로 배포할때 가장 주된 문제점이 안정성이다.
제품의 환경에 대해서는 쉽게 재 학습이 가능한 robust한 방법의 개발이 필요하다.
이 논문에서 우리는 GAN에서 영감을 받은 오토 인코더 기반의 모델을 제안했다.
이 모델은 인코더-디코더 구조의 적대적 학습이 GAN의 구조에 기반한 다른 방법들과 보다 더 안정적이면서 이상를 포함한 인풋의 reconstruction error를 어떻게 증폭시킬지를 학습하도록 한다.
이 구조는 확장성과 알고리즘 효율성 측면에서 기대치를 만족하는 학습을 빠르게 해낼 수 있다.
이 논문의 main contributions은 아래와 같다.
- 우리는 오토인코더와 적대적 학습의 한계점을 보정하면서 두 방법의 장점들을 합친 적대적 학습을 하는 오토인코더 구조를 제안했다.
- 우리는 공공으로 이용가능한 데이터에 대한 실증을 수행해서 robustness, 훈련속도, 성능을 분석한다.
- 여러 데이터에서 이상 탐지에 대해 state-of-the-art 성능을 얻어냈다.
Method
먼저 문제에 대해 정의하고, 우리 방법의 공식을 제시한다. 그 다음 우리 방법의 구현에 대해 설명한다.
Problem formulation
단일 변수의 시계열은 하나의 시간 스텝에서 하나의 값을 포함하고, 다중 변수의 시계열은 하나보다 더 많은 값들을 가지고 있다.
여기서는 우리는 다중 변수의 시계열에 대해 더 중점을 두었으며 각 시간 스텝에서 m개의 변수가 있다고 생각했다. 단일 변수 시계열은 m=1인 특정한 경우라고 생각하면 된다. x∈Rm
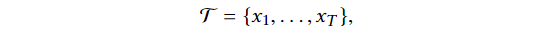
위에 있는 T(그리스문자)가 주어진 인풋이라고 했을 때 비지도 학습 문제에 대해 생각해보자. 이상 감지는 인풋에 없었던 관측에 대해 이루어진다. 인풋에는 오직 정상 데이터만 있다고 가정한다. 보지 못한 샘플과 정상 데이터셋 T의 차이가 anomaly score로 측정된다. 그 후 threshold와 비교해서 판별한다.
현재 시간 포인트와 과거 사이의 의존성을 모델링하기 위해 Wt 를 주어진 시간 t에서 길이 k의 시간 윈도우라고 정의한다. ( t-K+1부터 t까지의 값들의 집합)
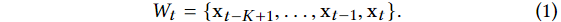
이러면 원래의 시계열 T를 윈도우들의 시퀀스로 변환할 수 있다. W = {W1, W2, …, WT}로 표현되는 윈도우들은 학습 인풋으로 사용된다.
우리의 이상 탐지 문제의 목표는 인풋에 없었던 윈도우 W’에 대해 윈도우의 anomaly score에 기반하여 정상인지 비정상인지 판단하는 것이다.
앞으로 W를 훈련 인풋 윈도우, W’를 인풋에 없었던 검증할 새로운 윈도우라고 할거다.
Unsupervised Anomaly Detection
Autoencoder(AE)는 encoder E와 decoder D를 결합한 비지도적 인공 신경망이다. 인코더 부분은 X를 인풋으로 받받아서 latent variables Z로 변환한다. 그리고 디코더는 latent variables Z를 다시 R로 인풋스페이스로 복원한다.
인풋 벡터 X와 복원된 R의 차이를 reconstruction error라고 부른다.
그래서 학습 목적은 이 에러를 최소화 하는 것을 목표로 한다. 이것은 아래와 같이 정의된다.
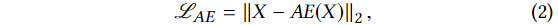
AE(X) = D(Z), Z=E(X) 를 만족하고 L2-norm을 사용한다.
오토인코더 기반의 anomaly detection은 reconstruction error를 anomaly score로 사용한다.
오직 정상데이터를 학습에만 사용한다. 그러면, AE는 정상 데이터는 잘 복원하지만, AE가 학습하지 못했던 비정상 데이터에 대해서는 잘 복원하지 못할 것이다. 따라서 anomaly score가 커지게 된다.
하지만, 만약 비정상인 정도가 매우 작다면(정상 데이터와 가깝다면) reconstruction error는 작아질 것이고 비정상은 감지되지 못할 것이다. 이거는 AE가 인풋 데이터와 가능한 가까운 데이터를 복원하도록 학습되기 때문이다.
이러한 문제점을 극복하기 위해, AE는 복원을 하기 전에 입력 데이터에 이상치가 있는지 확인할 수 있어야 한다.
인풋 샘플이 정상인지 아닌지 알아 내는 것이 Generative Adversarial Networks(GAN)의 특징이다.
AE기반 모델과 비슷하게, GAN기반 이상 탐지는 학습할 때 정상 데이터를 사용한다. 학습된 discriminator는 anomaly detector로 사용된다. 만약 인풋 데이터가 학습된 데이터의 분포와 다르다면, discriminator는 그 데이터가 generator로부터 왔다고 생각하고 가짜라고 판단한다.
그러나 GAN학습은 generator 와 discriminator 사이의 불균형을 일으키는 mode collapse와 non-convergence때문에 쉽지 않다.
USAD방법은 두 단계의 적대적 학습 방법을 사용하는 AE구조로 구성된다.
이러한 구조는 입력 데이터에 abnormal이 포함되어 있지 않은 경우를 구분할 수 있는 모델을 학습해서, 오토 인코더의 한계점을 극복할 수 있도록 한다.
또한, 오토 인코더 구조는 적대적 학습 중에 안정성을 얻게 해준다. 따라서 GAN에서 발생하는 collapse와 non-convergence mode문제를 해결한다.
USAD는 세 가지 요소로 구성되어 있다: 인코더 네트워크 E와 두 개의 디코더 네트워크 D1, D2이다.
아래 그림을 확인해 보면 세 개의 요소들이 같은 인코더를 공유하고 있는 두 개의 오토인코더 AE1
와 AE2로 구성된 구조로 연결되 있는 것을 확인할 수 있다.
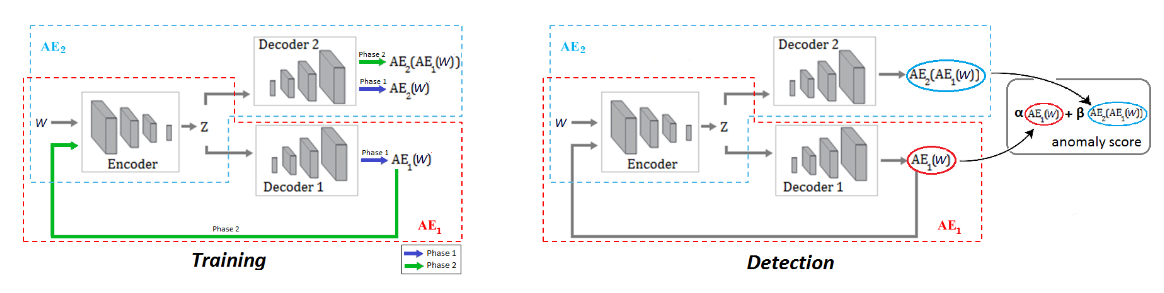
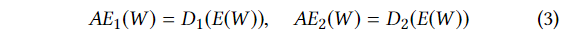
(3)의 식에 있는 오토인코더 들은 두 단계로 학습이 이루어 진다.
첫 번째로 두 개의 오토 인코더들이 정상 인풋 윈도우 W를 복원하는 것을 학습한다.
두 번째로 두 오토 인코더를 적대적으로 학습시킨다.
AE1는 AE2를 속이는 방향으로 학습하고, AE2는 데이터가 실제 데이터인 W인지 아니면 AE1으로 부터 복원된 데이터인지를 구분하는 방향으로 학습한다.
아래에서 자세하게 설명한다.
Phase 1: Autoencoder training.
첫 번째 단계에서의 목표는 각각의 AE를 원래의 인풋을 잘 복원하도록 학습하는 것이다. 인풋 데이터 W는 인코더 E에 의해 latent 공간 Z로 압축되고 각각의 디코더에 의해 복원된다. (2)번 식에 의해 로스 함수는 다음과 같다.
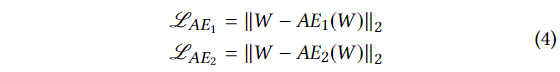
Phase 2: Adversarial training
두 번째 단계에서의 목표는 AE2를 실제 데이터와 AE1에서 오는 복원된 데이터를 잘 구분할 수 있도록 학습시키는 것과, AE1를 AE2를 잘 속일 수 있도록 학습시키는 것이다. AE1에서 오는 데이터는 다시 E에의해 Z로 압축되고, AE2에 의해 복원된다.
적대적 학습에서의 목적들을 설명하면, AE1의 목적은 W와 AE2의 차이를 최소화 하는 것이고, AE2의 목적은 이 차이를 최대화 하는 것이다.
즉, AE1은 AE2를 속이는 것을 학습하고, AE2는 실제와 AE1이 만든 데이터를 구분하는 것을 학습한다.
학습의 목적은 아래와 같다.
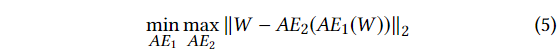
이 목적을 위한 로스 함수는 아래와 같다.
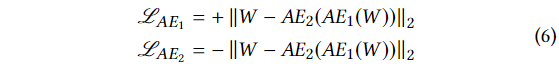
Two-phase training
우리의 구조에서 오토인코더들은 두가지 목적을 갖고있다.
AE1
- phase1: W의 복원 에러를 최소화
- phase2: W와 AE2에서 복원된 결과의 차이를 최소화
AE2
- phase1: W의 복원 에러를 최소화
- phase2: AE1에 의해 복원된 데이터의 복원 에러를 최대화
AE1과 AE2의 최종적인 로스 함수는 아래와 같다.
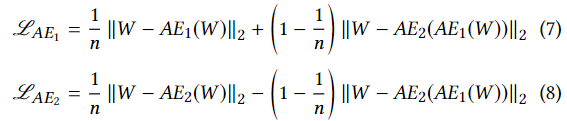
n은 학습 epoch를 뜻한다. 전체 훈련 과정은 Algorithm1에 요약되어 있다.
AE2의 입력이 인풋 데이터(W)일 경우 (4)번식이 로스가 되므로 , AE2가 엄밀하게는 GAN의 discriminator와는 다르다는 사실에 유의해야 한다. 만약 입력이 복원된 값이라면 (5) (6)번 식이 로스 함수로 사용된다.
Inference
탐지 단계 에서 비정상 점수는 아래와 같이 정의된다.
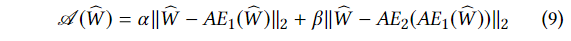
α, β는 α+β=1이며 false positives와 true positives 사이의 trade-off를 파라미터화 하는 용도로 사용된다.
만약 α가 β보다 더 크다면, 우리는 true positives의 개수와 false positives의 개수를 줄일 수 있다. 반대로 α가 β보다 더 작다면, 우리는 false positives의 개수를 늘리는 대신 true positives의 개수 또한 늘리 수 있다.
한마디로 α < β라면 높은 탐지 예민도를 갖게 되고, α > β라면 낮은 탐지 예민도를 갖게 된다.
이러한 파라미터들은 하나의 모델을 학습시키는 것으로 다양한 예민도의 비정상 점수를 얻을 수 있어서 유용하게 사용 될 수 있다.

Conclusion
Auto Encoder와 Adversarial Training방법을 사용해서 시계열 데이터에서 비정상을 탐지하는 모델이다.
adversrial training을 사용하지만 GAN과는 약간 다른 방법을 사용한다.
실제로 간단한 테스트를 진행해 본 결과 GAN 특유의 학습할 때 불안정하다는 점이 별로 느껴지지 않았다.
이상치가 있는 시계열 데이터를 구하는 것은 어렵기 때문에 그냥 시계열 데이터에 가우시안 노이즈를 조금 넣는 것으로 테스트를 진행해본 결과 육안으로는 전혀 보이지 않는 노이즈 구간도 잘 탐지해낸 것을 확인할 수 있었다.
모델의 구조 자체는 지금까지 논문을 보면서 구현해본 모델중 가장 간단하다고 할 수 있을 정도로 간단했지만, 나쁘지 않은 성능을 가지고 있는거 같아서 적용하기도 쉽고 좋은 방법이라는 생각이 들었다.
모델에서 RNN도 사용하지 않고 Linear Layer만을 사용하는 데도 성능이 좋다는 점이 신기했다.