[논문번역] Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI 2021)
(AAAI-21 Outstanding Paper Award)
paper: https://arxiv.org/pdf/2012.07436v3.pdf
code: https://github.com/zhouhaoyi/Informer2020
긴 길이의 시계열 예측에 특화된 효율적인 트랜스 포머 기반 모델
Abstract
전력 소모량 계획과 같은 많은 실제 세상의 어플리케이션은 긴 길이의 시계열이다. Long sequence time-series forecasting(LSTF) 은 인풋과 아웃풋 사이의 긴 범위의 의존성을 정확히 포착하는 모델의 높은 예측 용량을 요구한다.
최근의 연구들은 Transformer가 예측 용량을 증가시킬 수 있는 잠재력을 가지고 있다는 것을 보여줬다. 그러나 이차 시간복잡도, 높은 메모리 사용, encoder-decoder구조에 내제된 한계점과 같은 Transformer를 LSTF에 바로 적용하지 못하게 하는 몇몇의 심각한 문제가 있다.
이러한 문제를 해결하기 위해, 우리는 Informer라는 이름의 LSTF를 위한 효율적인 Transformer기반의 모델 설계했다. 이 모델은 세 가지의 독특한 특징을 가지고 있다.
- O(LlogL)의 시간복잡도와 메모리 사용량을 가지는 Probsparse self-attention 메커니즘이 sequences’ dependency alignment에서 비교할만한 성능을 보인다.
- 계단식 레이어 인풋을 절반으로 줄여서 self-attention이 지배적인 attention을 집중시키고, 효과적으로 매우 긴 인풋 시퀀스를 다룬다.
- 생성적인 스타일의 디코더(generative style decoder)는 개념적으로 단순하지만 긴 시계열 시퀀스의 예측을 단계별 방식이 아닌 한번의 forward 연산으로 긴 시퀀스 예측의 추론 속도를 급속도로 증가시켰다.
4개의 큰 범위의 데이터셋의 광범위한 실험은 Informer가 기존의 존재하는 방법들을 많이 능가하는 것을 보여줬고, LSTF 문제의 새로운 해결책을 제공했다.
Introduction
시계열 예측은 센서 네트워크 모니터링, 에너지와 스마트 그리드 관리, 경제와 재정, 질병 전파 분석과 같은 많은 분야에서 중요한 요소이다. 이러한 시나리오들에서, 우리는 장기적으로 예측을 하기 위해(LSTF) 과거의 행동의 시계열 데이터의 상당히 많은 양을 활용할 수 있다. 그러나 기존의 방법들은 대부분 48칸 이하의 길이를 예측하는 것과 같이 짧은 기간의 문제에 적합하게 설계되었다. 이러한 추세가 LSTF에 대한 연구를 지연시킬 정도로 긴 시퀀스가 모델의 예측 능력에 점점 더 부담을 주고 있다.
실험에 의거한 예시로, 아래의 그림에서 실제 데이터셋에서의 예측 결과를 보여준다. LSTM 네트워크가 변압기의 1시간 간격의 온도를 짧은 간격의 주기(12point, 0.5일)에서 긴 간격의 주기까지 (480point, 20일) 예측한다.
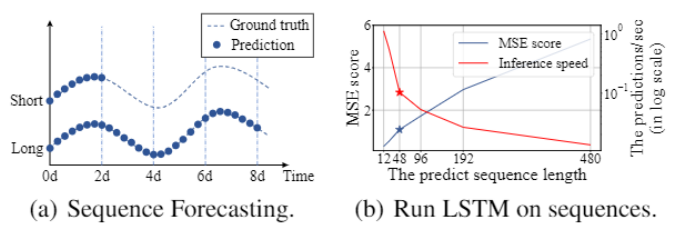
예측 길이가 48보다 더 커질 때 전반적인 성능 차이는 상당했다. MSE는 충분하지 않은 성능 수준으로 올라가고, 추론 속도는 빠르게 떨어졌고, LSTM모델은 실패하기 시작했다.
LSTF의 가장 주된 목표는 점점 더 길어지는 시퀀스 요구를 맞추기 위해 예측 용량을 증가시키는 것이다. 그러기 위해 다음 사항이 필요하다.
(a) 매우 긴 범위의 정렬 능력
(b) 긴 시퀀스 입력과 출력에 대한 효율적인 작업
최근에 Transformer 모델이 긴 범위의 의존성을 포착하는 데에 RNN모델보다 우월한 성능을 보여줬다. self-attention 메커니즘은 네트워크 신호 전파 경로의 최대 길이를 이론상 가장 짧은 O(1) 까지 줄일 수 있고 recurrent 구조를 회피할 수 있다. 이를 사용하는 Transformer는 LSTF 문제에서 뛰어난 잠재력을 보여줬다.
그럼에도 불구하고 self-attention 메커니즘은 L의 길이의 인풋, 아웃풋에서 L차 계산과 메모리를 소비하기 때문에 요구사항 (b)를 위반한다. 일부 대규모의 Transformer 모델들은 자원들을 쏟아부어서 NLP 작업의 좋은 결과를 얻어낸다. 그러나 수십개의 GPU에 대한 훈련과 비싼 구축 비용 때문에 이러한 모델이 실제 LSTF 문제를 해결하지 못하게 한다. self-attention 메커니즘과 Transformer 구조의 효율성은 LSTF 문제에 적용하는데에 걸림돌이 된다.
그래서 이 논문에서, 우리는 다음 질문의 답을 찾았다 : Transformer 모델을 더 높은 예측 용량을 가지도록 계산, 메모리, 구조를 효율적으로 개선할 수 있을까?
Vanilla Transformer는 LSTF문제를 해결할 때 3가지의 큰 한계를 가지고 있다.
- self-attention의 이차 계산 복잡도.
self-attention 메커니즘의 canonical dot-product는 layer당 O(L2)의 시간 복잡도와 메모리 사용도를 가지고 있다. - 쌓여있는 레이어들의 긴 input에 대한 메모리 병목 현상.
J개 만큼 쌓여있는 encoder/decoder 레이어들의 총 메모리 사용량은 O(J * L2)이다. 이는 긴 시퀀스의 입력을 수신하는 모델의 확장성을 제한한다. - 긴 아웃풋을 예측 할 때 속도가 급락한다.
vanilla Transformer의 동적인 디코딩은 한 단계 씩 추론하기 때문에 RNN 기반의 모델만큼 느리다.
self-attention의 효율성을 증가시키기 위한 몇몇의 사전 연구들이 있다. The Sparse Transformer, LogSparse Transformer, LongFormer 들은 모두 그들의 효율성이 제한될 때 한계점 1을 해결하고 self-attention 메커니즘의 복잡도를 O(LlogL)로 감소시키기 위해 휴리스틱 방법을 사용했다. Reformer도 역시 지역적으로 예민한 hashing self-attention으로 O(LlogL)을 달성했다. 그러나 오직 극도로 긴 시퀀스에서만 사용가능했다. 더 최근에 Linformer는 선형 복잡도 O(L)을 주장했다. 그러나 project matrix가 실제의 긴 시퀀스의 인풋에서는 고정되어 있지 않기 때문에 O(L2)로 악화될 위험이 있다. Transformer-XL과 Compressive Transformer는 긴 범위의 의존성을 포착하기 위해 보조의 hideen states를 사용했다. 이것은 limitation 1은 해결할 수 있지만 병목현상의 효율성을 해소 하는데에는 불리하다.
모든 이러한 연구들은 주로 limitation 1을 해결하는데에 집중하고 limitation 2, 3은 여전히 LSTF의 풀리지 않은 문제점으로 남아있다. 예측 용량을 증가시키기 위해, 제안된 Informer에서 우리는 모든 limitations들을 해소하고 뛰어난 효율성을 얻어냈다.
이를 위해, 우리의 연구는 이 세가지 문제를 명쾌하게 파헤친다. 우리는 self-attention 메커니즘 안에 있는 희소성을 조사하고, 네트워크 구성 요소들을 개선하고, 넓은 범위의 실험을 진행했다.
이 논문의 기여에 대한 요약은 아래와 같다.
- 우리는 LSTF 문제에서 예측 용량을 성공적으로 증가시키는 Informer를 제안한다. 이는 긴 길이의 시계열의 아웃풋과 인풋 사이의 의존성을 포착할 때 Transformer-like 모델의 잠재력을 입증했다.
- 우리는 canonical self-attention을 효율적으로 대체하기 위해 ProbSparse self-attention 메커니즘을 제안한다. 이것은 dependency alignements에서 O(LlogL)의 시간 복잡도와 메모리 사용 사용도를 달성했다.
- 우리는 J-stacking layers에서 attention score를 지배할 수 있고, 총 공간 복잡도를 O((2-e)LlogL)까지 많이 줄일 수 있는 self-attention distilling operation을 제안한다. 이것은 긴 인풋을 받아드리는 것을 돕는다.
- 우리는 긴 길이의 아웃풋을 오직 한번의 forward step만으로 얻어내기 위해 generative style decoder를 제안한다. 동시에 추론 단계에서 누적되는 에러를 피할 수 있다.
Preliminary
우리는 먼저 LSTF 문제의 정의를 설명한다.
고정된 window size의 예측 설정에서, 우리는 인풋 Xt = {x1, …, xLx}를 시간 t에서 가지고, 아웃풋은 거기에 상응하는 예측값인 Yt = {y1, …, yLy}을 가진다. LSTF 문제는 과거의 연구보다 아웃풋 길이 Ly가 더 길고, 특징의 차원은 단일 변수로 제한되지 않는다. (dy>=1)
Encoder-decoder architecture
많은 유명한 모델들은 인풋 표현 Xt를 hidden state 표현 Ht로 encode하고, 아웃풋 표현 Yt를 Ht에서 decode한다. 추론 과정은 “dynamic decoding”이라고 불리는 step-by-step과정을 포함한다. decoer가 새로운 hidden state hk+1 을 이전의 상태인 hk과 k번째 아웃풋으로 계산하고 (k+1) 번째 시퀀스 yk+1을 예측한다.
Input Representation
시계열 인풋의 전역 positional context 와 지역 temporal context를 개선시키기 위해 시간균일한 인풋 표현이 주어진다. 좀더 자세한 설명을 Appendix B 에 넣어놓았다.
Methodology
시계열 예측의 존재하는 방법들은 대략적으로 두개의 카테고리로 그룹지을 수 있다.
전통적인 시계열 모델들은 시계열 예측에서 믿을만한 도구의 역할을 한다. 딥러닝 기술들은 RNN과 그것의 변형을 사용하여 encoder-decoder 예측 방식으로 주로 개발한다.
우리의 제안된 Informer 는 LSTF문제를 해결하는 동안 encoder-decoer 구조를 유지한다. 아래의 그림에서 모델의 개요에 대해 나와있고 아래에서 자세한 설명을 하겠다.
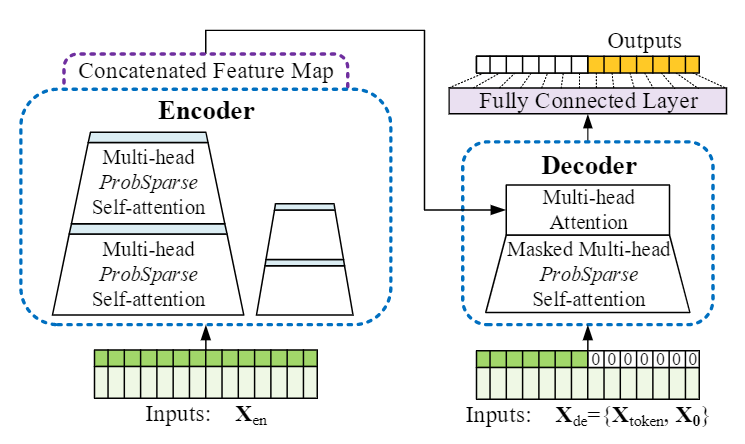
informer model overview
left: 인코더는 거대한 긴 시퀀스 인풋(녹색)을 받는다. 우리는 canonical self-attention을 제안된 ProbSparse self-attention으로 대체한다. 파란색 사다리꼴은 네트워크의 사이즈를 많이 감소시키면서, attention 을 추출하기 위한 self-attention 정제 과정이다. 쌓여있는 복제된 layer는 굳건함을 증가시키다.
right: 디코더는 목표 부분이 0으로 패딩되어 있는 긴 시퀀스 인풋을 받아드리고, 피쳐 맵의 weighted attention의 구성을 측정한다. 그리고 generative sytle로 아웃풋 요소(오렌지색) 를 즉시 예측한다.
Efficient Self-attention Mechanism
canonical self-attention은 튜플 인풋들(query, key, value) 에 기반하여 정의 되어 있다. 이는 Softmax(QKT/root(d)) V 와 같은 scaled dot-product를 수행한다. self-attention 메커니즘에 대해 더 자세히 설명하면, qi, ki, vi를 각각 Q,K,V의 i 번째 행이라고 하자. 아래의 식에 의해 i번째 query의 어텐션은 kernel smoother로 정의 된다.
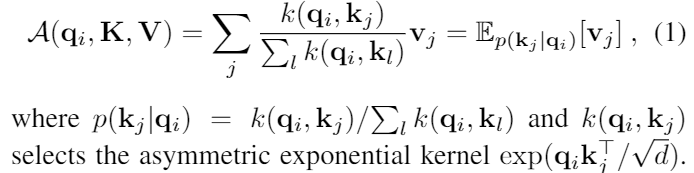
self-attention은 확률 p(kj|qi)를 계산하는 것을 기반으로 values와 획득한 아웃풋들을 조합한다. 이것은 2차의 dot-product 계산 횟수가 필요하고 O(LQLK)의 메모리 사용량이 필요하다. 이것은 예측 용량을 향상시킬 때의 주된 문제점이다.
일부 과거의 시도들은 self-attention 확률의 분포가 잠재적인 희소성을 가지고 있다는 것을 보여주었다. 그리고 그것들은 성능을 유지하면서 p(kj|qi)에 대한 “선택적인” 카운팅 전략을 설계했다. (희소성을 가지고 있기 때문에 중요한 것만 선택해도 된다.)
Sparse Transformer는 row output과 column input을 포함하고, 희소성은 분리된 공간의 상관관계에서 발생한다. LogSparse Transformer 는 self-attention의 순환하는 패턴에 주목했고 각 셀이 지수함수의 step size로 이전 셀과 연결되도록 했다. Longformer는 더 복잡한 희소 형태까지 이전의 두개의 연구를 확장했다.
그러나 이러한 방법들은 휴리스틱 방법을 따르는 이론적 분석에 국한되며, 동일한 전략으로 multi-head self-attention을 다루기 때문에 추가적인 개선을 못한다.
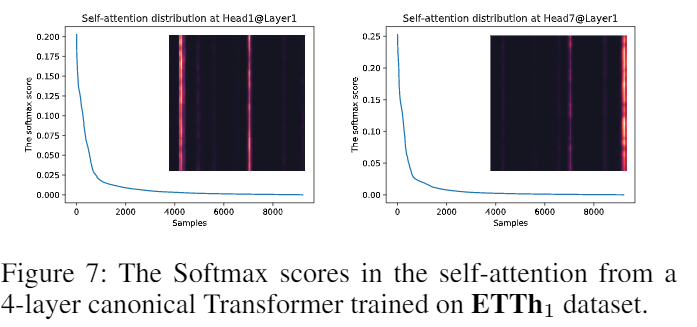
우리의 접근방식에 동기를 부여하기 위해, 우리는 canonical self-attention의 학습된 attention 패턴에 대한 정성적인 평가를 수행한다. “희소적인” self-attention 점수는 long tail 분포를 형성한다. 그 예시는 아래와 같다.
그러면 어떻게 희소한 부분을 구분할 것인가?
Query Sparsity Measurement
(1)번 식에서 모든 key에 대한 i번째 query의 attention은 확률 p(kj|qi)로 정의 되고 아웃풋은 v와 그것의 구성이다. 많은 dot-product pairs 는 uniform distribution에서 벗어나 해당하는 query의 attention probability 분포를 따른다. 만약 p(kj|qi)가 uniform distribution q(kj|qi) = 1/Lk 와 가까워 진다면 self-attention은 values V의 사소한 합이 되고, residential input으로 된다.
당연히도 분포 p와 q의 “유사성”은 “중요한” query가 뭔지 구분하는데 사용될 수 있다. 우리는 “유사성”을 Kullback-Leibler divergence로 측정한다. Kullback-Leibler divergence는 아래와 같다.
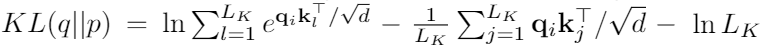
상수를 없애면, 우리는 i번째 쿼리의 희소성을 아래와 같이 측정할 수 있다.
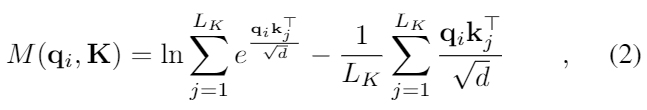
첫번째 부분은 모든 key에 대한 qi의 Log-Sum-Exp (LSE)이고, 두번째 부분은 그것들의 평균이다.
만약 i번째 query가 M(qi, K)보다 크다면, 그것의 attention probability p는 더 “다양”하고 long tail self-attention 분포에서 앞쪽 부분의 지배적인 dot-product pairs를 가지고 있을 확률이 높다.
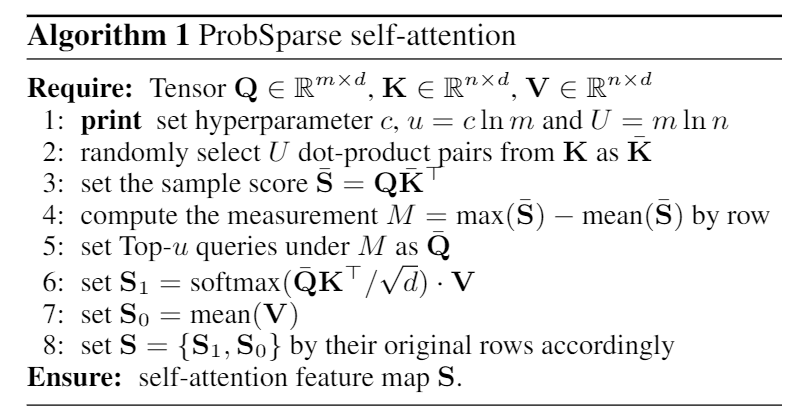
ProbSparse Self-attention
제안된 측정에 기반해서, 우리는 각각의 key들에 대해 u dominant queries들에게만 계산하는 ProbSparse self-attention을 만들었다. 그 식은 아래와 같다.
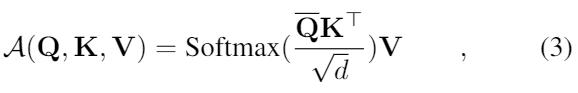
Q^bar 는 q와 동일한 사이즈를 가진 희소 행렬이고 오직 희소성 측정 M(q,K)에 의한 Top-u queries들만 포함한다. 상수 sampling factor c에 의해 제어되는, u = c lnLQ로 설정했다. 이는 ProbSparse self-attention 을 각각의 query-key 에 대해오직 O(lnLQ)의 dot-product만 계산하면 되도록 하고, layer 메모리 사용량을 O(LK ln LQ)가 되로록 한다.
multi-head 관점에서 볼때 , 이 attention은 각각의 head에서 다른 희소 query-key pairs를 생성하고 결과에서 심각한 정보 손실을 피한다.
그러나, 측정 M(qi, K)를 위한 모든 쿼리들의 탐색은 각각의 dot-product pairs의 계산이 필요하다. (2차식의 O(LQLK)). 게다가 LSE 과정은 잠재적 수치 안정성 문제를 기지고 있다. 이러한 사실에 동기가 되어, 우리는 query sparsity 측정의 효율적인 획득을 위한 실증적인 근사법을 제안했다.
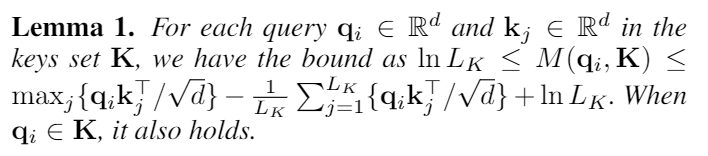
lemma 1에 의해 (Appendix D.1에 증명되어 있다) 우리는 max-mean 측정을 아래와 같이 제안했다.
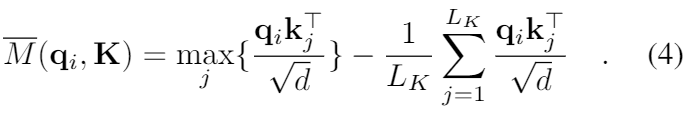
Top-u의 대략적인 범위는 경계 완화에서 유지된다. long tail disgribution 에서는 , 우리는 M^bar(qi, K)를 계산하기 위해 오직 임의의 샘플 U = LK ln LQ dot-product pairs를 랜덤 샘플하기만 하면 된다. 그러면 우리는 희소의 Top-u 를 Q^bar로 선택할 수 있다. M^bar(qi,K) 에서의max-operater는 0 값에 덜 민감하고 수치적으로 안정되어 있다.
실제로 self-attention 계산에서 query와 key의 인풋 길이는 일반적으로 동일하다.
LQ = LK = L 인경우 총 ProbSparse self-attention의 시간 복잡도와 공간 복잡도는 O(LlnL)이다.
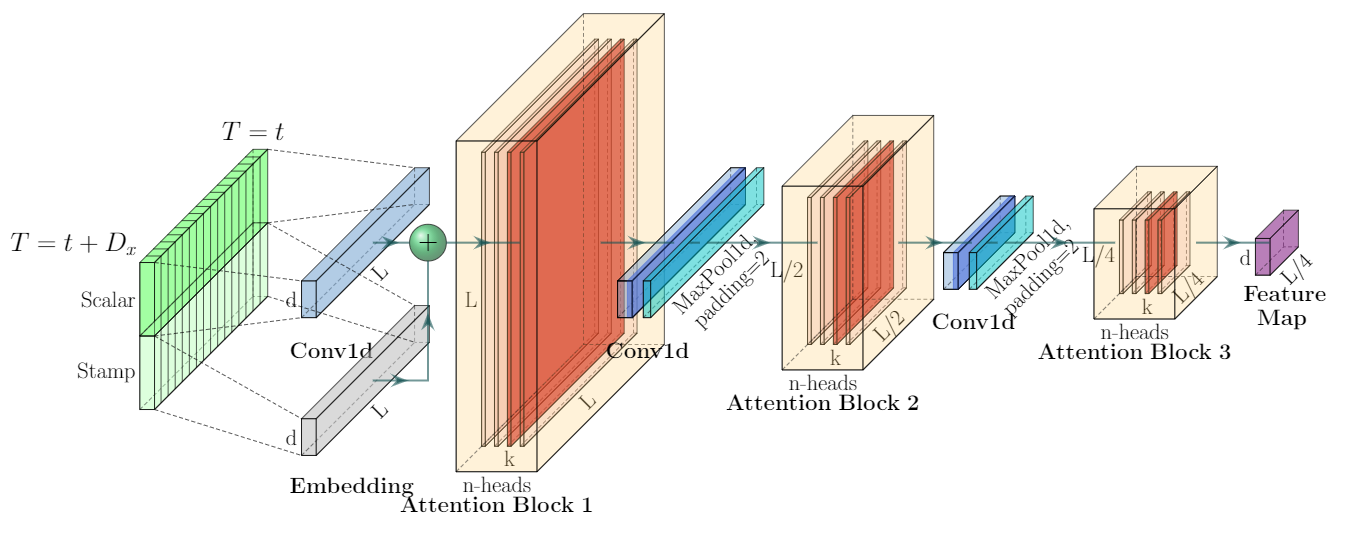
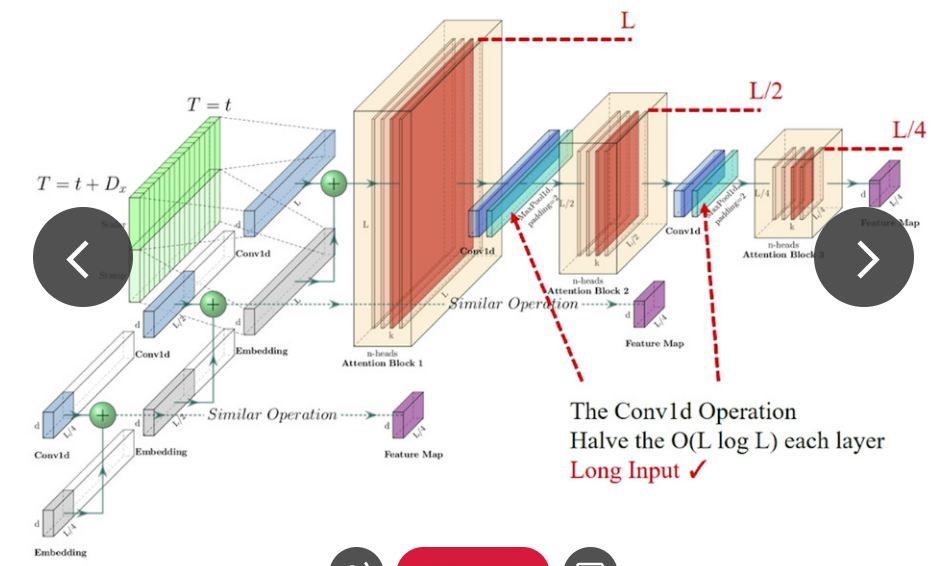
Encoder: Allowing for ProcessingLonger Sequential Inputs under the Memory Usage Limitation
인코더는 긴 시퀀셜 인풋의 굳건한 긴 범위의 의존성을 추출하도록 설계되었다. input representation후에 , t 번째 시퀀스 인풋 Xt 는 행렬 Xten의 모양으로 된다. 우리의 인코더의 그림은 아래와 같다.
더 자세한 그림
Informer의 인코더안에 있는 하나의 stack이다.
(1) 수평의 스택들중 하나는 인코더 복제본중 하나를 나타낸다.
(2) 하나는 전체 입력 시퀀스를 입력받는 메인 스택이다. 그리고 두번째 스택은 인풋의 반으로 잘린 것을 받고 그 이후의 스택들은 그것을 반복한다.
(3) 빨간색 리에어는 dot-product 행렬이고, 각각의 레이어에서 self-attention distilling을 적용하여 계단식으로 감소한다.
(4) 모든 스택들의 feature map들을 합친것이 인코더의 아웃풋이다.
Self-attention Distilling
ProbSparse self-attention 메커니즘의 순수한 결과로, 인코더의 피쳐맵은 V값의 줄어든 조합을 가지고 있다. 우리는 distilling 작업을 통해 지배적인 특징을 가진 우월한 것에게 특권을 부여했다. 그리고 다음 레이어에서 집중된 self-attention feature map을 만든다. 그것은 Attention blocks의 n-heads weights matrix 를 보면서 인풋의 시간 차원을 많이 trim한다. dilated convolution에 영감을 받아서우리의 j번째 layer에서 (j+1) 번째 layer로 진행되는 “distilling” 과정은 아래와 같다.
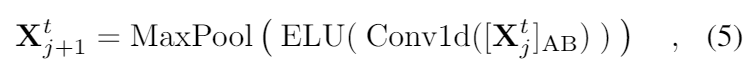
[]AB는 attention block 을 표현한다. 이것은 Multi-head ProbSparse self-attention과 1-D convolutional filter (kernel width=3)을 시간축에서 ELU activation function과 함께 가지고있다. 우리는 2의 stride를 가지고 있는 max-pooling layer를 추가하였고 layer를 쌓은 이후에 Xt를 절반으로 잘라서 downsample을 했다. 이것은 전체 메모리 사용량을 O((2-e)logL)로 만들었고, e는 작은 숫자이다.
distilling 작업의 굳건함을 증가시키기 우해, 우리는 main stack과 똑같이 절반은 인풋으로 만들었다. 그리고 계속해서 self-attention distilling layer의 숫자를 한번에 한 레이어씩 계속해서 줄여나가서 피라미드 처럼 만들었다.
그래서 우리는 모든 스택들의 아웃풋을 합쳐서 인코더의 최종 hidden representation을 얻어낸다.
Decoder: Generating Long Sequential Outputs Through One Forward Procedure
우리는 표준의 디코더 구조를 사용했다, 그리고 그것은 두개의 동일한 multihead attention layers의 스택으로 구성되어 있다. 그러나 긴 예측에서의 급격한 속도 저하를 완화시키기 위해 생성적인 추론이 사용 된다. 우리는 아래의 벡터로 디코더의 입력으로 넣어주었다.
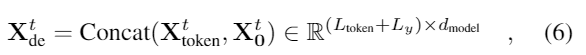
Xttoken은 시작 토큰이고 XtO은 목표 시퀀스의(0으로 설정됨) placeholder이다. 마스킹된 multi-head attention은 ProbSparse self-attention 계산에서 -무한대로 적용된다. 이것은 각각의 위치가 다음 위치로 이동하는 것을 방지해서 auto-regressive를 피한다.
fully connected layer가 최종 아웃풋을 얻어낸다. 그리고 그것의 사이즈 dy는 우리가 수행하는게 univariate forecasting인지 multivariate forecasting인지에 따라 다르다.
Generative Inference
start token은 NLP의 “dynamic decoding”에서 효과적으로 적용된다. 그리고 우리는 그것을 생성적인 방법으로 확장한다. 특정한 표시를 토큰으로 선택하는 것 대신, 우리는 아웃풋 시퀀스 전의 이전 슬리아스 같은 것을 Ltoken long sequence를 인풋 인풋 시퀀스에서 샘플한다.
예를 들어 168 포인트를 예측할 때(온도 예측에서 7일에 해당), 우리는 목표 시퀀스 이전의 알고있는 5일의 데이터를 “start-token”으로 사용한다. 그리고 generative-style inference decoder를 Xde = {X5d, XO}를 입력으로 사용한다.
XO는 목표 시퀀스의 타임 스탬프를 포함하고 있다. (i.e. 목표의 날짜). 그리고 우리의 제안된 디코더는 평범한 encoder-decoder 구조의 시간이 많이 소모되는 “dynamic decoding”이 아니라 한번의 과정으로 아웃풋을 예측한다. 자세한 성능 비교는 computation efficiency 섹션에 나와있다.
Loss function
우리는 목표 시퀀스를 예측할 때 MSE loss function 을 선택했다. 그리고 로스는 디코더의 아웃풋에서 전체 모델로 뒤로 전파된다.
Conclusion
요즘 자연어처리 말고도 다양한 분야에도 적용되는 시도가 많이 이루어지고 있는 Transformer를 시계열 예측에 사용한 모델이다.
Transformer의 시계열 예측에서의 문제점들을 모두 해결했고 성능도 매우 좋은 것 같다.
실제로 실험해본 결과 시간, 정확도 측면에서 모두 우수해서 내가 본 딥러닝 기반 시계열 예측 방법 중에서는 가장 좋은 방법인 것 같다.