[성능비교] Time Series Imputation - BRITS(NeurIPS 2018), NAOMI(NeurIPS 2019)
Time Series Imputation 프로젝트
시계열 데이터에서 결측치 대체는 예측하려는 부분보다 미래의 데이터도 사용해야 하고 예측해야할 부분의 길이와 위치가 임의로 주어지기 때문에 시계열 예측과는 다른 문제로 분류된다.
시계열 데이터에서의 결측치는 흔히 발견되는 문제이고, 분류나 예측같은 task를 수행할때 결측치를 미리 채워넣고 진행하면 성능이 더 좋아지기 때문에 시계열 데이터에서 결측치 대체도 중요한 전처리 과정이다.
전에 교통데이터를 이용한 시계열 예측을 진행하기 위해 시계열 예측 방법에 대해 조사할 때는 시계열 예측은 사람들이 많이 시도하는 문제여서 그런지 보편적으로 많이 사용되는 방법들이 많이 알려져 있었지만, 시계열 결측치 대체 문제에 대해서는 널리 사용되는 보편적인 방법같은 것을 찾기 힘들었다.
그래서 다양한 논문을 직접 찾아서 읽어보았고 그 중에서 좋아보였던 BRITS, NAOMI라는 두 가지 방법에 대해서 코드를 구현한 후 결과를 확인해 보았다.
각 방법에 대한 논문은 아래에서 확인할 수 있다.
각 방법에 대한 구현은 아래에서 확인할 수 있다.
Overview
각 방법들의 결측치의 길이별 결측치 대체의 MAPE값은 아래와 같다.
MAPE
| Method | Missing Length: 5 | Missing Length:10 | Missing Length:20 | Missing Length:30 | Missing Length:50 |
|---|---|---|---|---|---|
| BRITS | 1.891 | 3.546 | 7.241 | 11.775 | 15.310 |
| NAOMI | 2.236 | 2.796 | 4.815 | 7.192 | 5.381 |
결과값을 확인해 보면 BRITS는 결측치의 길이가 길어질 수록 확실하게 성능이 안좋아지는 것을 확인할 수 있었다. 이는 RNN의 특징인 멀어질수록 정보가 희미해진다는 점과 temporal decay factor를 사용한다는 점 때문에 어쩔 수 없는 결과인 것 같다.
그에 비해 NAOMI는 긴 길이의 결측치를 효과적으로 대체하기 위해 나온 모델인 만큼 결측치의 길이가 길어져도 계속 좋은 성능을 유지한 것을 확인할 수 있었다.
BRITS
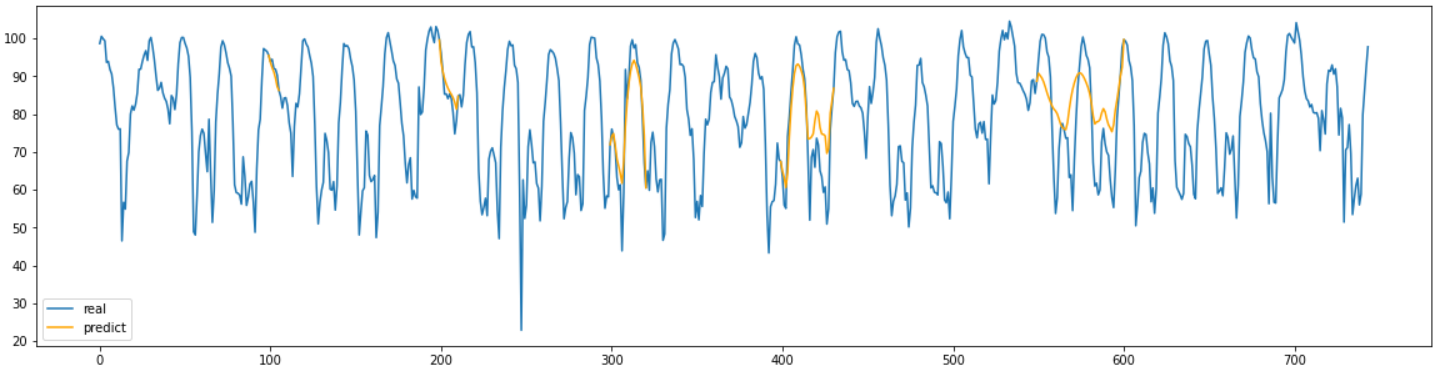
그래프를 확인해 보면 길이가 짧은 결측 구간에 대해서는 잘 예측을 했지만, 길이가 길어질 수록 기존의 정보가 희미해져서 진폭이 줄어드는 현상이 일어나는 것을 확인할 수 있었다.
epoch를 늘리면 조금씩 완화되는 경향은 있었지만 아무리 많은 epoch를 돌려도 길이가 30이상으로 넘어가면 제대로 예측을 하지 못하는 것을 확인했다.
NAOMI
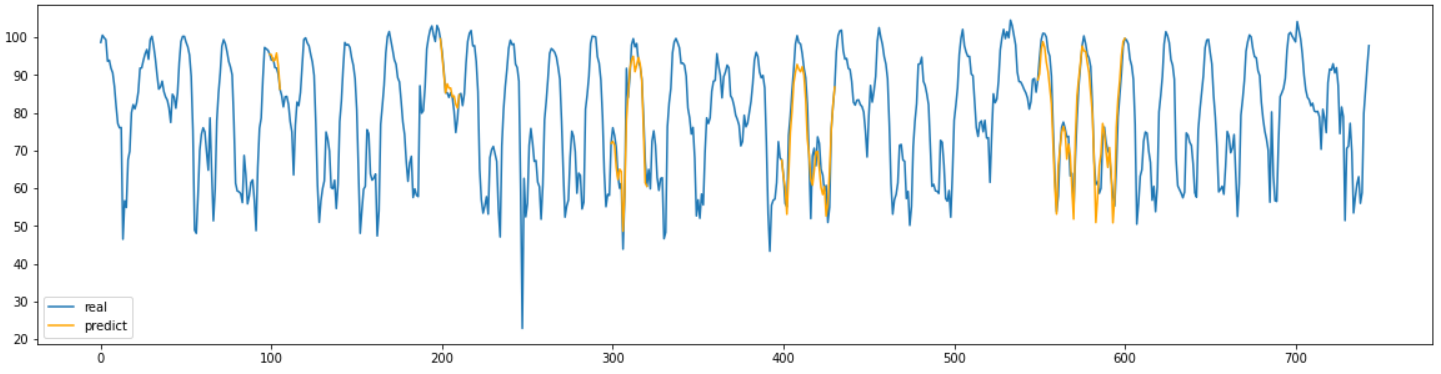
NAOMI는 BRITS와는 달리 결측치의 길이가 길어도 매우 좋은 결측치 대체 효과를 확인할 수 있었다.
모든 구간에 대해서 거의 완벽하게 결측치를 예측해낸 것을 그래프를 통해 확인할 수 있다.
Conclusion
결과만 봤을 때는 NAOMI가 BRITS의 성능을 압도하며 일반적인 상황에서도 사용가능한 좋은 모델인 것으로 생각된다.
하지만 train dataset을 만드는 과정을 보면, BRITS모델은 결측치가 포함된 데이터 자체로 정보를 전달하면서 학습을 진행하지만, NAOMI모델은 충분한 양의 연속된 정상 데이터를 가지고 학습을 진행한 후 결측치를 예측한다.
따라서 NAOMI모델의 경우 특정 사이즈의 윈도우 크기로 train dataset을 만들어 주어야 하는데 결측 데이터가 잦은 빈도로 존재할 경우 train dataset을 만들기가 힘들다.
충분한 양의 연속된 정상 데이터가 존재하고 결측 구간이 비교적 길다면 NAOMI 모델을 사용하는 것이 더 효과적이고, 결측치의 길이가 짧고 연속된 정상데이터를 추출하기 힘들정도로 결측치가 잦은 빈도로 존재한다면 BRITS모델을 사용하는 것이 더 효과적일 것이라고 생각된다.
결측치 대체에 대한 task를 수행해본 결과 전에 진행했던 시계열 예측과는 상당히 다른 방식으로 진행되고 있었고 아무래도 결측구간 이후의 정보도 활용하다 보니까 단순 예측보다는 훨씬 더 좋은 정확도를 가지고 있는 것 같았다.
시계열 데이터를 활용할 때 결측치가 존재한다면, 단순한 평균값이나 선형보간 같은 방법보다 위와같은 deep learning기반의 결측치 대체 방법을 사용하는것이 더 좋은 결과를 낼 수 있을 것 같다.