[성능비교] Time Series Forecasting - ARIMA, FP, LSTM, Transformer, Informer
Time Series Forecasting 프로젝트
한 시간 간격으로 측정 되어 있는 한 달치 특정 구간의 평균 속도 데이터를 이용하여 마지막 일주일 간의 평균 속도를 예측하는 task를 ARIMA(SARIMAX), Facebook Prophet, LSTM, Transformer, Informer 이렇게 다섯 가지의 방법으로 수행해 보았다.
각 방법들에 대한 구현은 아래와 같다.
Overview
각 방법들의 최종 결과는 아래와 같다.
| Method | ARIMA:day | ARIMA:week | Facebook Prophet | LSTM (seq2seq) | Transformer | Informer |
|---|---|---|---|---|---|---|
| MAPE | 8.00 | 8.75 | 9.85 | 8.99 | 8.40 | 7.75 |
| Training Time | 2.5sec | 1.5min | 0.11sec | 15min (GPU) | 5min (GPU) | 2min (GPU) |
| Inference Time | 0.01sec | 0.17sec | 0.003sec | 0.06sec | 0.02sec | 0.04sec |
단순히 MAPE만 비교해보면 Informer > Arima > Transformer > LSTM > FP 이지만 그 차이가 별로 크지 않고 각 모델별 특성이 다르기 때문에 실제 시계열 예측이 필요할 때는 필요에 따라 목적에 맞는 모델을 선택할 필요가 있어보인다.
ARIMA (SARIMAX)
ARIMA는 전통적인 통계기반의 시계열 예측 모델이다.
ARIMA로만 예측을 진행했을 때는 효과가 거의 없어서 주기성을 추가로 고려한 SARIMAX를 사용해서 예측을 진행했다. SARIMAX에는 예측할 주기를 입력해 주어야 하는데 1일, 7일을 주기로 각각 예측을 진행했다.
ARIMA (SARIMAX):day
MAPE: 8.00
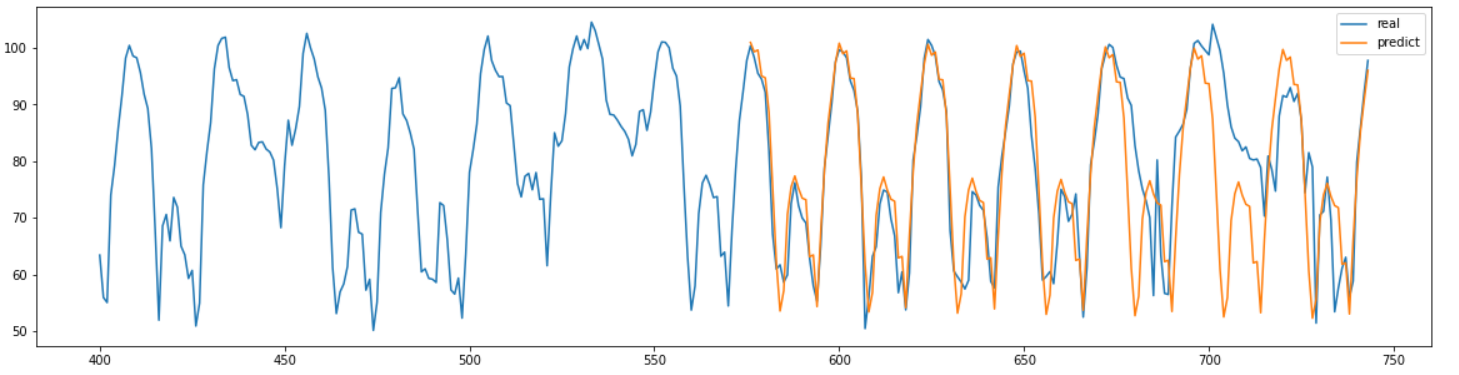
하루를 주기로 설정하고 예측한 결과는 위와 같다.
하루만큼의 예측값이 계속 반복되는 형태인 것을 확인할 수 있다.
정확도는 나쁘지 않지만 하루치 예측이 계속 반복되는 형태이기 때문에 날마다 다른 부분은 포착하지 못한 것을 확인했다.
ARIMA (SARIMAX):week
MAPE: 8.75
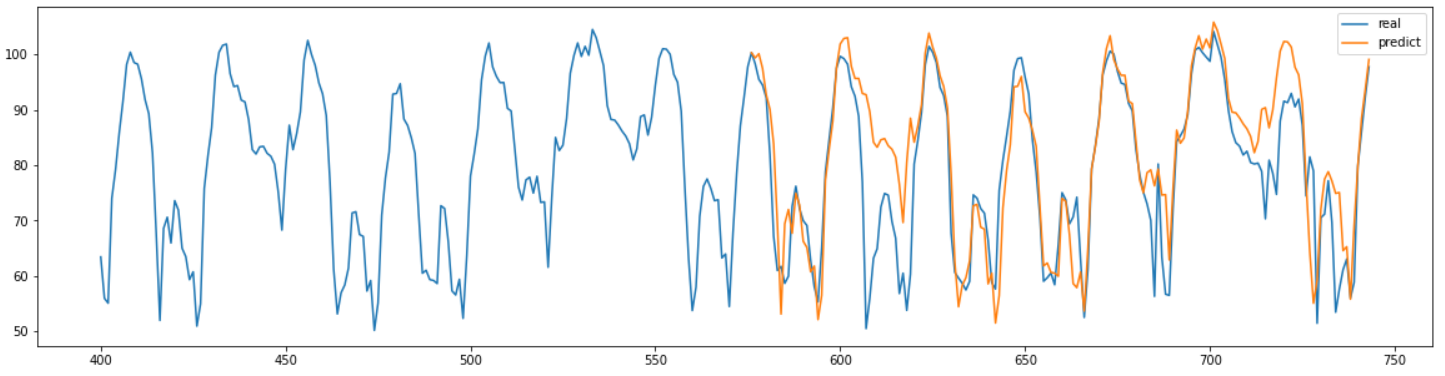
일별 특성을 반영시키기 위해 일주일을 주기로 SARIMAX를 학습시킨 결과는 위와 같다.
정확도 자체는 오히려 더 낮아졌지만 일별 특성을 이전보다는 더 잘 잡아낸 것으로 보인다.
임의의 날짜의 교통상태가 궁금할 때는 첫번째 방법을, 특정 요일의 교통 상태가 궁금할 때는 두 번째 방법을 사용하는 것이 더 좋아 보인다.
Conclusion
SARIMAX는 입력한 주기에 따라 예측 결과가 크게 바뀌는 것을 알 수 있었다. 알고싶은 데이터의 범위에 따라 적절하게 주기를 설정해야 좋은 결과를 얻을 수 있다.
방법자체는 간단하고 빠르고 나쁘지 않은 정확도를 가지고 있지만 주기를 입력해야 하기 때문에 주기가 없는 데이터이거나 주기를 알기 힘든 데이터에서는 사용할 수 없어서 특정한 상황에만 사용할 수 있는 방법이다.
주기만 알고 있다면 빠르고 좋은 정확도를 얻어낼 수 있는 모델이어서 상황이 맞다면 가장 먼저 적용해 볼 수 있는 방법인거 같다.
Facebook Prophet
페이스북에서 제공하는 Facebook Prophet을 이용해서 시계열 예측을 진행해 보았다.
MAPE: 9.85
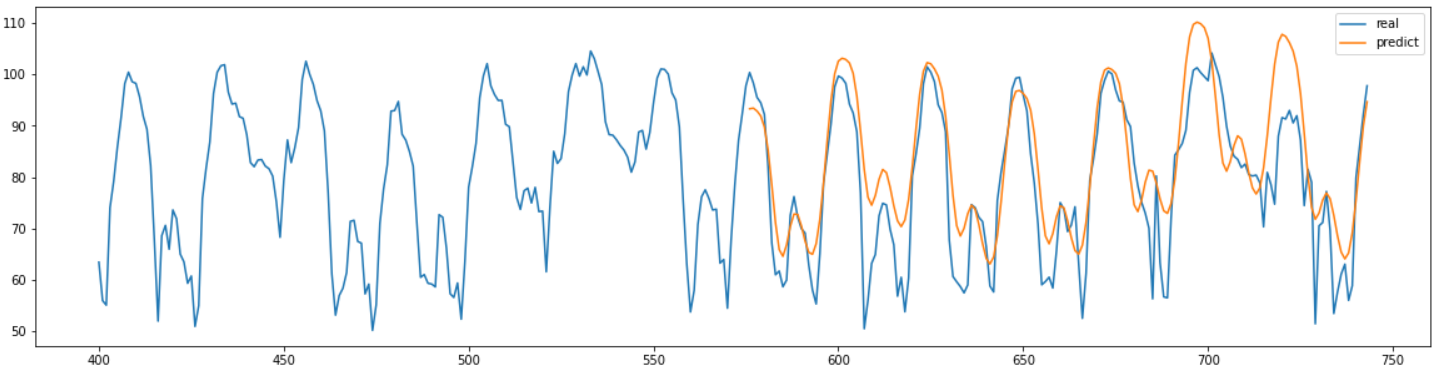
예측 결과는 위와 같다.
결과를 보면 뭔가 둥글둥글하게 예측을 하는 것을 확인할 수 있다.
모델 생성이나 예측 과정이 모두 코드 1줄로 가능해서 구현하는 데에는 가장 편한 방법이었다.
별다른 인풋없이 데이터만 넣으면 학습, 예측이 가능하고 학습도 금방 이루어진다.
매우 간편한 방법치곤 성능도 나쁘지 않아 쉽게 사용하기에 좋은 방법인거 같다.
LSTM (seq2seq)
seq2seq 모델이라고 불리는 Encoder Decoder LSTM구조를 만들어서 학습을 진행했다.
MAPE: 8.99
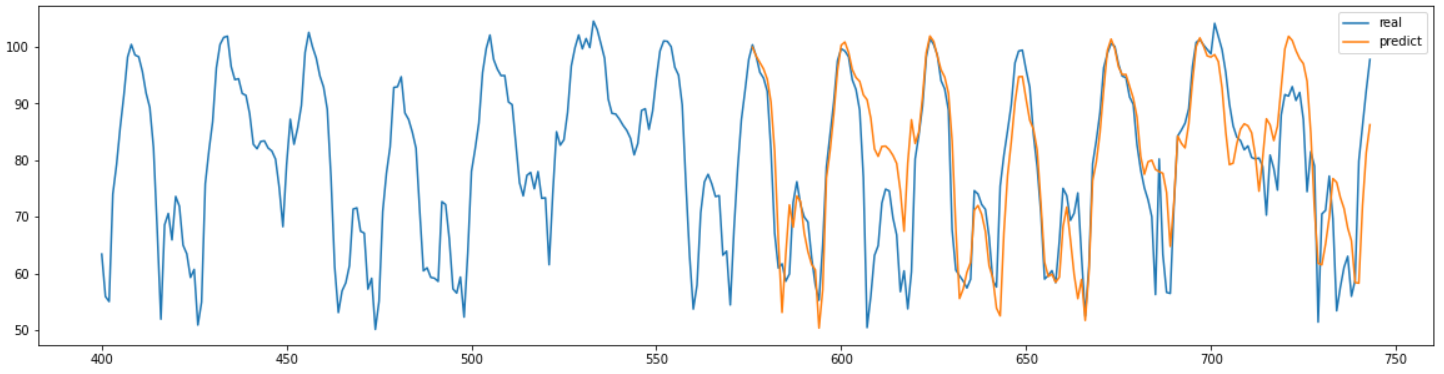
결과를 확인해 보면 시간적 특성을 잘 예측한 것을 알 수 있다.
조절해야할 하이퍼 파라미터가 많지만 훈련시간이 길어서 많은 실험을 해보지 못한것 치고는 좋은 결과가 나온 것 같다.
하이퍼 파라미터를 좀더 튜닝한다면 더 좋은 결과가 나올 수 있을거라고 생각된다.
딥러닝을 활용한 시계열 예측 방법 중 가장 많이 사용되는 방법인 만큼 무난한 결과가 나온 것 같다.
Transformer
자연어 처리에 주로 사용되는 모델인 Transformer를 사용해서 시계열 예측을 진행해 보았다.
Transformer를 사용한 시계열 예측에 대한 정형적인 모델은 없어서 직접 모델링한 후 학습을 진행했다.
MAPE: 8.40
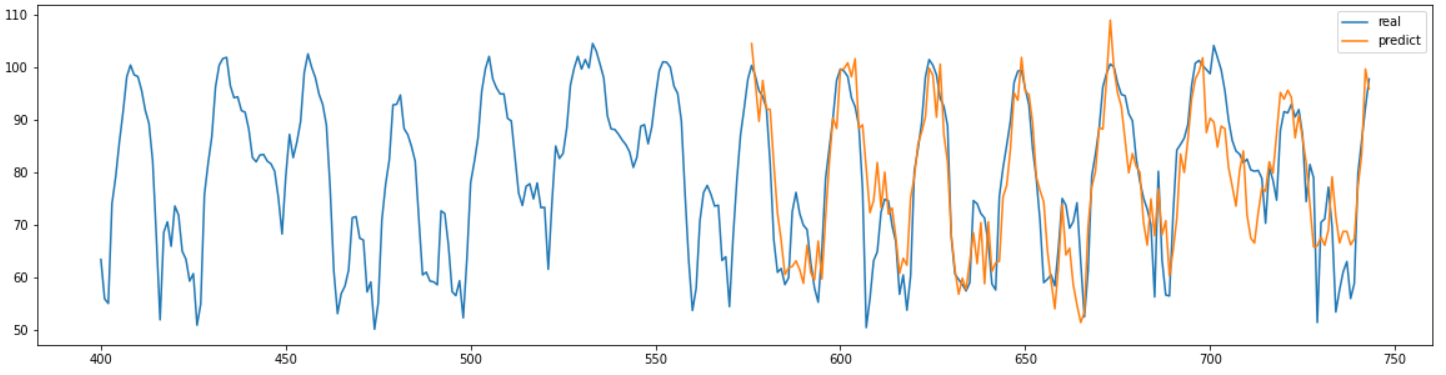
결과를 보면 뭔가 뾰족뾰족한게 불안정해 보이는 모양을 가지고 있다. MAPE는 좋은 값이 나왔지만 학습 과정에서 loss가 수렴하는 지점을 찾아내기가 굉장히 힘들었다.
그래도 내 생각대로 직접 모델링한 모델이 나쁘지 않은 성능을 보인것 같아서 만족스러웠다.
Transformer 모델은 정말 활용가능성이 많은 모델이라는 생각이 들었다.
Informer
Transformer 가 가진 긴 시계열 예측에서의 문제점들을 해결한 Informer라는 모델을 이용하여 예측을 진행했다.
MAPE: 7.75
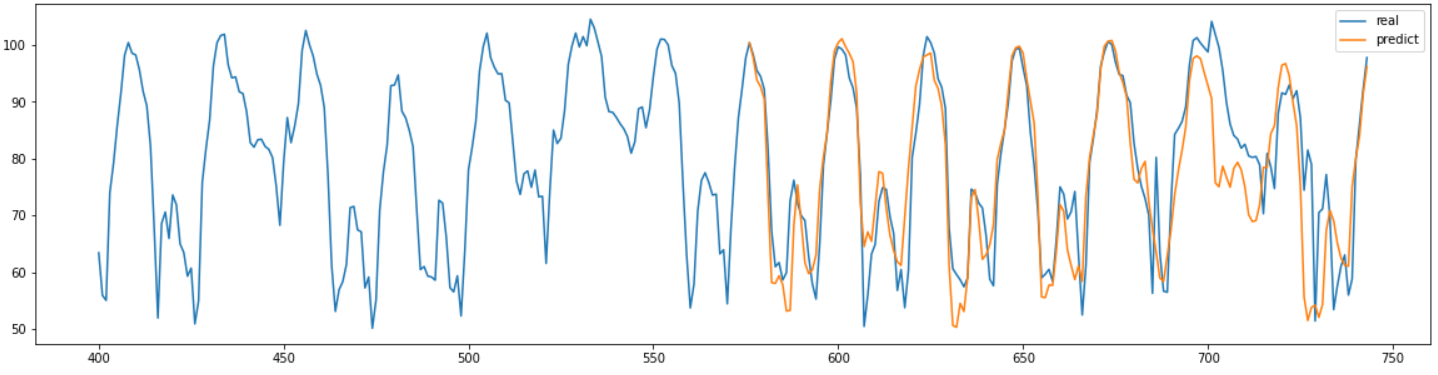
결과를 보면 굉장히 실제와 비슷하게 잘 예측을 한 것을 확인할 수 있다. MAPE도 가장 좋은 수치가 나왔으며 학습시간도 별로 길지 않았다.
학습 시간도 다른 DL 모델들에 비해 가장 짧음에도 더 좋은 성능을 보여주었기 때문에 가장 뛰어난 모델이라는 생각이 들었다.
그래도 MAPE 1~2차이 이기 때문에 어떠한 상황에서도 가장 뛰어나다고 확신할 정도는 아니지만 대부분의 상황에서 좋은 성능을 보여줄것 같다.
Conclusion
시계열 예측이라는 문제를 동일한 데이터에서 5가지의 방법으로 수행해 보았다. 그 결과 각 방법들간의 장단점을 확인할 수 있었다.
시계열 데이터 처리는 DL모델보다 통계기반 모델이 더 효과적이라는 의견이 많은데 실제로 통계기반 모델이 시간적으로 훨씬 빠르고, 성능도 큰 차이는 없었다.
하지만 충분한 하이퍼 파리미터 튜닝 과정을 진행하지 않았음에도 DL모델들이 조금이나마 좋은 성능을 가지고 있는 것을 확인했고, univariate가 아니라 multivariate라면 DL모델이 더욱 유리해 질것이라고 생각한다.
특히, transformer 기반의 Informer라는 모델은 확실히 짧은 시간으로 좋은 성능을 보여줬고, transformer기반의 시계열 예측 모델이 계속 연구된다면 시계열 예측을 하는 최적의 모델이 나올 수도 있다는 생각이 들었다.