[코드구현] Time Series Imputation - BRITS (NeurIPS 2018)
한 시간 간격으로 측정 되어 있는 한 달치의 특정 구간 평균 속도 데이터를 이용하여 임의로 결측치를 만들고 결측치 대체해보는 task를 수행해 보았다.
데이터는 도로교통공사의 오픈 데이터를 직접 가공하였으며 아래에서 다운로드할 수 있다.
전에 번역했던 BRITS: bidirectional recurrent imputation for time series 논문을 코드로 구현하였으며 github의 official code를 참고했다.
paper: https://arxiv.org/pdf/1805.10572.pdf
code: https://github.com/caow13/BRITS
BRITS는 양방향 RNN과 temporal decay factor등을 이용해 결측치를 대체하는 모델이며 논문의 자세한 내용은 아래에 있다.
Import Module
import torch
import torch.optim as optim
from torch.autograd import Variable
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.nn.parameter import Parameter
import torch.nn.functional as F
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from tqdm import tqdm
import ujson as json
import math
필요한 모듈들을 import해준다.
Load Data
데이터를 로드한다.
df = pd.read_csv("서인천IC-부평IC 평균속도.csv",encoding='CP949')
df2 = pd.DataFrame()
df2["time"] = pd.to_datetime(df["집계일시"],format="%Y%m%d%H%M")
df2["value"] = df["평균속도"]
missing_range = [(100,105),(200,210),(300,320),(400,430),(550,600)]
for start,end in missing_range:
df2.iloc[start:end,1] = np.nan
plt.figure(figsize=(20,5))
plt.plot(df2["value"])
plt.show()
df2.to_csv("data.csv", index=False)
데이터는 한달치의 1시간 간격의 평균 속도 데이터로 총 744개의 데이터가 있다.
결측치는 5~50범위의 다양한 길이로 갈수록 결측범위가 길어지도록 임의의 구간에 직접 만들어 주었다.
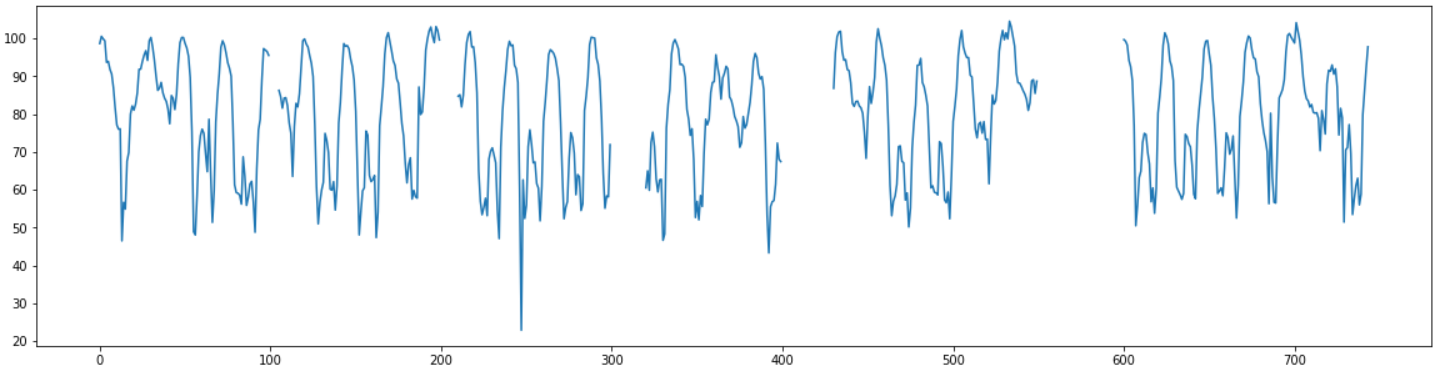
Make Dataset
데이터셋을 만들 때 데이터에 대한 각종 정보들을 담은 json파일을 생성하고, 그 json파일을 읽어서 생성한다.
def parse_delta(masks, dir_):
if dir_ == 'backward':
masks = masks[::-1]
deltas = []
for h in range(len(masks)):
if h == 0:
deltas.append(1)
else:
deltas.append(1 + (1 - masks[h]) * deltas[-1])
return np.array(deltas)
def parse_delta(masks, dir_):
if dir_ == 'backward':
masks = masks[::-1]
deltas = []
for h in range(len(masks)):
if h == 0:
deltas.append(1)
else:
deltas.append(1 + (1 - masks[h]) * deltas[-1])
return np.array(deltas)
def parse_rec(values, masks, evals, eval_masks, dir_):
deltas = parse_delta(masks, dir_)
# only used in GRU-D
forwards = pd.DataFrame(values).fillna(method='ffill').fillna(0.0).values
rec = {}
rec['values'] = np.nan_to_num(values).tolist()
rec['masks'] = masks.astype('int32').tolist()
# imputation ground-truth
rec['evals'] = np.nan_to_num(evals).tolist()
rec['eval_masks'] = eval_masks.astype('int32').tolist()
rec['forwards'] = forwards.tolist()
rec['deltas'] = deltas.tolist()
return rec
def makedata(datapath):
df = pd.read_csv(datapath)
length = len(df)
# df.columns = ["Time", "Velocity"]
df = df[["time", "value"]]
mean = df["value"].mean()
std = df["value"].std()
data = df
evals = []
for h in range(len(df)):
evals.append(data["value"].iloc[h])
evals = (np.array(evals) - mean) / std
shp = evals.shape
values = evals.copy()
masks = ~np.isnan(values)
eval_masks = (~np.isnan(values)) ^ (~np.isnan(evals))
masks = masks.reshape(shp)
eval_masks = eval_masks.reshape(shp)
label = 0
rec = {'label': label}
# prepare the model for both directions
rec['forward'] = parse_rec(values, masks, evals, eval_masks, dir_='forward')
rec['backward'] = parse_rec(values[::-1], masks[::-1], evals[::-1], eval_masks[::-1], dir_='backward')
rec = json.dumps(rec)
fs = open('./traffic.json', 'w')
fs.write(rec)
fs.close()
return length
위에 있는 makedata함수를 사용하여 학습에 사용할 다양한 정보가 담긴 traffic.json파일을 생성한다.
class MySet(Dataset):
def __init__(self, file):
super(MySet, self).__init__()
self.content = open(file).readlines()
indices = np.arange(len(self.content))
val_indices = np.random.choice(indices, len(self.content) // 5)
self.val_indices = set(val_indices.tolist())
def __len__(self):
return len(self.content)
def __getitem__(self, idx):
rec = json.loads(self.content[idx])
if idx in self.val_indices:
rec['is_train'] = 0
else:
rec['is_train'] = 1
return rec
def collate_fn(recs):
forward = list(map(lambda x: x['forward'], recs))
backward = list(map(lambda x: x['backward'], recs))
def to_tensor_dict(recs):
values = torch.FloatTensor(list(map(lambda r: r['values'], recs))).unsqueeze(-1)
masks = torch.FloatTensor(list(map(lambda r: r['masks'], recs))).unsqueeze(-1)
deltas = torch.FloatTensor(list(map(lambda r: r['deltas'], recs))).unsqueeze(-1)
evals = torch.FloatTensor(list(map(lambda r: r['evals'], recs))).unsqueeze(-1)
eval_masks = torch.FloatTensor(list(map(lambda r: r['eval_masks'], recs))).unsqueeze(-1)
forwards = torch.FloatTensor(list(map(lambda r: r['forwards'], recs))).unsqueeze(-1)
return {'values': values, 'forwards': forwards, 'masks': masks, 'deltas': deltas, 'evals': evals, 'eval_masks': eval_masks}
ret_dict = {'forward': to_tensor_dict(forward), 'backward': to_tensor_dict(backward)}
ret_dict['labels'] = torch.FloatTensor(list(map(lambda x: x['label'], recs))).unsqueeze(-1)
ret_dict['is_train'] = torch.FloatTensor(list(map(lambda x: x['is_train'], recs))).unsqueeze(-1)
return ret_dict
def get_loader(file, batch_size = 64, shuffle = True):
data_set = MySet(file)
data_iter = DataLoader(dataset = data_set, batch_size = batch_size,num_workers = 4, shuffle = shuffle, pin_memory = True, collate_fn = collate_fn)
return data_iter
위에 있는 get_loader함수를 사용하여 최종적으로 훈련에 사용할 torch의 DataLoader를 생성한다.
def to_var(var, device):
if torch.is_tensor(var):
var = Variable(var)
var = var.to(device)
return var
if isinstance(var, int) or isinstance(var, float) or isinstance(var, str):
return var
if isinstance(var, dict):
for key in var:
var[key] = to_var(var[key], device)
return var
if isinstance(var, list):
var = map(lambda x: to_var(x, device), var)
return var
나중에 사용할 데이터를 tensor로 바꾸고 device를 바꿔주는 함수를 작성한다.
Model
논문의 BRITS는 multivariate 데이터에서 사용하는 모델이지만, 여기서 사용하는 데이터는 univariate데이터이므로 univarite데이터에서 사용하는 모델인 Brits_i을 사용한다.
class Brits_i(nn.Module):
def __init__(self, rnn_hid_size, impute_weight, label_weight, seq_len, device):
super(Brits_i, self).__init__()
self.rnn_hid_size = rnn_hid_size
self.impute_weight = impute_weight
self.label_weight = label_weight
self.seq_len = seq_len
self.device = device
self.build()
def build(self):
self.rits_f = Rits_i(self.rnn_hid_size, self.impute_weight, self.label_weight,self.seq_len, self.device)
self.rits_b = Rits_i(self.rnn_hid_size, self.impute_weight, self.label_weight,self.seq_len, self.device)
def forward(self, data):
ret_f = self.rits_f(data, 'forward')
ret_b = self.reverse(self.rits_b(data, 'backward'))
ret = self.merge_ret(ret_f, ret_b)
return ret
def merge_ret(self, ret_f, ret_b):
loss_f = ret_f['loss']
loss_b = ret_b['loss']
loss_c = self.get_consistency_loss(ret_f['imputations'], ret_b['imputations'])
loss = loss_f + loss_b + loss_c
predictions = (ret_f['predictions'] + ret_b['predictions']) / 2
imputations = (ret_f['imputations'] + ret_b['imputations']) / 2
ret_f['loss'] = loss
ret_f['predictions'] = predictions
ret_f['imputations'] = imputations
return ret_f
def get_consistency_loss(self, pred_f, pred_b):
loss = torch.abs(pred_f - pred_b).mean() * 1e-1
return loss
def reverse(self, ret):
def reverse_tensor(tensor_):
if tensor_.dim() <= 1:
return tensor_
indices = range(tensor_.size()[1])[::-1]
indices = Variable(torch.LongTensor(indices), requires_grad = False)
# if torch.cuda.is_available():
indices = indices.to(self.device)
return tensor_.index_select(1, indices)
for key in ret:
ret[key] = reverse_tensor(ret[key])
return ret
def run_on_batch(self, data, optimizer, epoch=None):
ret = self(data)
if optimizer is not None:
optimizer.zero_grad()
ret['loss'].backward()
optimizer.step()
return ret
def binary_cross_entropy_with_logits(input, target, weight=None, size_average=True, reduce=True):
if not (target.size() == input.size()):
raise ValueError("Target size ({}) must be the same as input size ({})".format(target.size(), input.size()))
max_val = (-input).clamp(min=0)
loss = input - input * target + max_val + ((-max_val).exp() + (-input - max_val).exp()).log()
if weight is not None:
loss = loss * weight
if not reduce:
return loss
elif size_average:
return loss.mean()
else:
return loss.sum()
class TemporalDecay(nn.Module):
def __init__(self, input_size, rnn_hid_size):
super(TemporalDecay, self).__init__()
self.rnn_hid_size = rnn_hid_size
self.build(input_size)
def build(self, input_size):
self.W = Parameter(torch.Tensor(self.rnn_hid_size, input_size))
self.b = Parameter(torch.Tensor(self.rnn_hid_size))
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.W.size(0))
self.W.data.uniform_(-stdv, stdv)
if self.b is not None:
self.b.data.uniform_(-stdv, stdv)
def forward(self, d):
gamma = F.relu(F.linear(d, self.W, self.b))
gamma = torch.exp(-gamma)
return gamma
class Rits_i(nn.Module):
def __init__(self, rnn_hid_size, impute_weight, label_weight, seq_len, device):
super(Rits_i, self).__init__()
self.rnn_hid_size = rnn_hid_size
self.impute_weight = impute_weight
self.label_weight = label_weight
self.seq_len = seq_len
self.device = device
self.build()
def build(self):
self.input_size = 1
self.rnn_cell = nn.LSTMCell(self.input_size * 2, self.rnn_hid_size)
self.regression = nn.Linear(self.rnn_hid_size, self.input_size)
self.temp_decay = TemporalDecay(input_size = self.input_size, rnn_hid_size = self.rnn_hid_size)
self.out = nn.Linear(self.rnn_hid_size, 1)
def forward(self, data, direct):
values = data[direct]['values']
masks = data[direct]['masks']
deltas = data[direct]['deltas']
evals = data[direct]['evals']
eval_masks = data[direct]['eval_masks']
labels = data['labels'].view(-1, 1)
is_train = data['is_train'].view(-1, 1)
h = Variable(torch.zeros((values.size()[0], self.rnn_hid_size)))
c = Variable(torch.zeros((values.size()[0], self.rnn_hid_size)))
h, c = h.to(self.device), c.to(self.device)
x_loss = 0.0
y_loss = 0.0
imputations = []
for t in range(self.seq_len):
x = values[:, t, :]
m = masks[:, t, :]
d = deltas[:, t, :]
gamma = self.temp_decay(d)
h = h * gamma
x_h = self.regression(h)
x_c = m * x + (1 - m) * x_h
x_loss += torch.sum(torch.abs(x - x_h) * m) / (torch.sum(m) + 1e-5)
inputs = torch.cat([x_c, m], dim = 1)
h, c = self.rnn_cell(inputs, (h, c))
imputations.append(x_c.unsqueeze(dim = 1))
imputations = torch.cat(imputations, dim = 1)
y_h = self.out(h)
y_loss = binary_cross_entropy_with_logits(y_h, labels, reduce = False)
# only use training labels
y_loss = torch.sum(y_loss * is_train) / (torch.sum(is_train) + 1e-5)
y_h = torch.sigmoid(y_h)
return {'loss': x_loss * self.impute_weight + y_loss * self.label_weight, 'predictions': y_h,\
'imputations': imputations, 'labels': labels, 'is_train': is_train,\
'evals': evals, 'eval_masks': eval_masks}
def run_on_batch(self, data, optimizer, epoch = None):
ret = self(data, direct = 'forward')
if optimizer is not None:
optimizer.zero_grad()
ret['loss'].backward()
optimizer.step()
return ret
기존 코드에서는 seq_len이 고정이었는데 입력값으로 받아서 조절할 수 있도록 수정했다.
Train
완성된 모델과 데이터로 학습을 진행한다.
path = "data.csv"
device = torch.device("cuda")
df = pd.read_csv(path)
data = df["value"]
length = len(df)
makedata("data.csv")
#(hidden_state_dim, impute_weight, label_weight, length, device)
#여기서는 classification 없이 imputation만 하므로, impute weight를 1, label weight를 0으로 설정한다.
model = Brits_i(108, 1, 0, length, device).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.01)
data_iter = get_loader('./traffic.json', batch_size=64)
모델과 데이터로더를 생성한다.
epoch = 100
model.train()
progress = tqdm(range(epoch))
for i in progress:
tl=0.0
for idx, data in enumerate(data_iter):
data = to_var(data,device)
ret =model.run_on_batch(data,optimizer, i)
tl += ret["loss"]
progress.set_description("loss: {:0.6f}".format(tl/len(data_iter)))
loss: 287.349976: 100%|██████████| 100/100 [03:46<00:00, 2.27s/it]
100번의 epoch로 학습을 진행한다.
Evaluate
학습된 모델의 결과를 확인한다.
def evaluate():
model.eval()
imputations = []
for idx, data in enumerate(data_iter):
data = to_var(data, device)
ret = model.run_on_batch(data, None)
eval_masks = ret['eval_masks'].data.cpu().numpy()
imputation = ret['imputations'].data.cpu().numpy()
imputations += imputation[np.where(eval_masks == 1)].tolist()
imputations = np.asarray(imputations)
return imputation
def predict_result():
imputation = evaluate()
scaler = StandardScaler()
scaler = scaler.fit(df["value"].to_numpy().reshape(-1,1))
result = scaler.inverse_transform(imputation[0])
return result[:,0]
결과를 만드는 함수를 선언한다.
result =predict_result()
real = pd.read_csv("서인천IC-부평IC 평균속도.csv",encoding='CP949')
plt.figure(figsize=(20,5))
plt.plot(df["value"], label="real", zorder=10)
plt.plot(result, label="predict")
plt.legend()
plt.show()
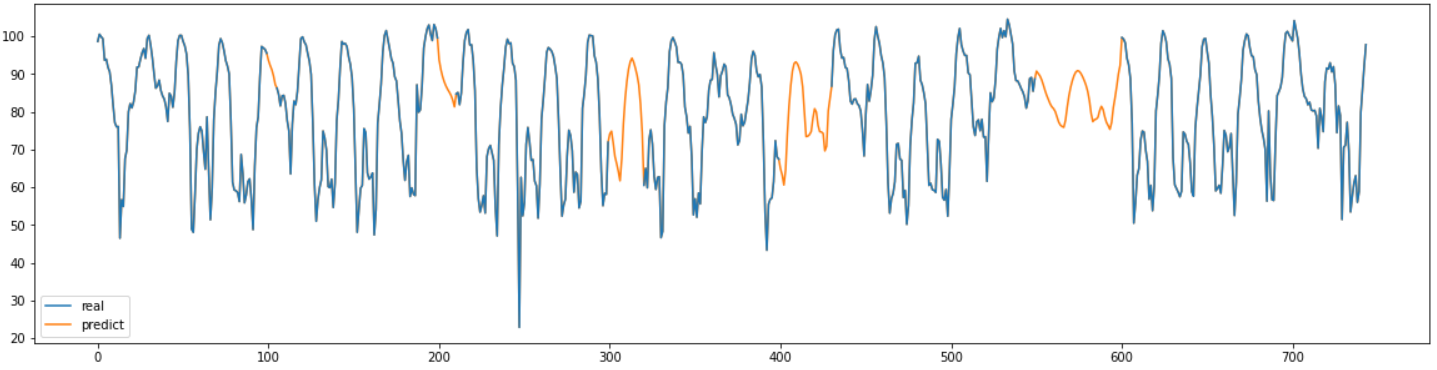
plt.figure(figsize=(20,5))
plt.plot(real["평균속도"], label="real")
lb = "predict"
for start, end in missing_range:
plt.plot(range(start-1,end+1), result[start-1:end+1], label=lb, color="orange")
lb=None
plt.legend()
plt.show()
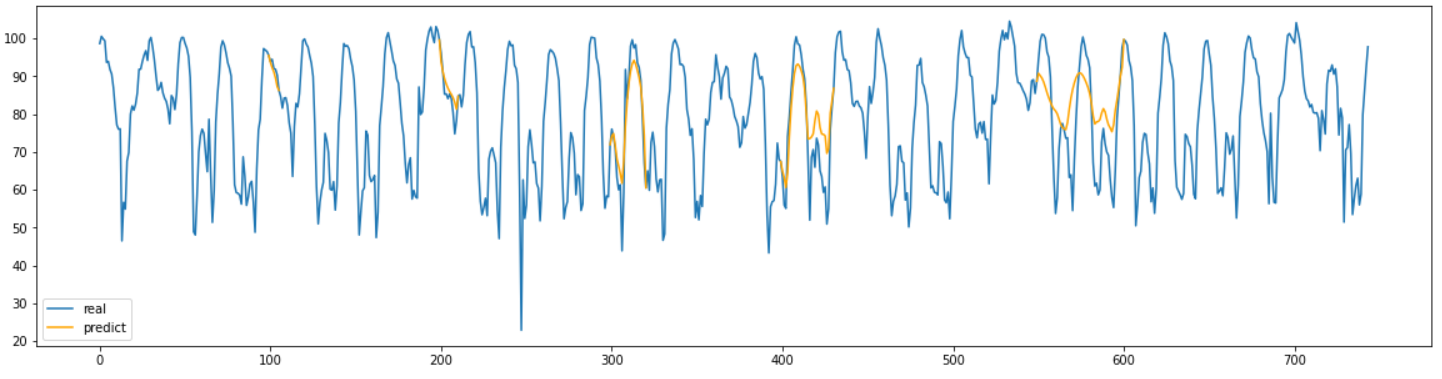
결과를 확인해 보면 결측 구간이 짧은 부분은 어느정도 잘 예측을 했지만 결측구간이 길어질 수록 점점 부정확해 지는 것을 확인할 수 있다.
결측치의 길이가 길어질수록 예측을 하는 진폭이 줄어드는 모양을 확인할 수 있다.
def MAPEval(y_pred, y_true):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
realval = real["평균속도"].values
for start,end in missing_range:
print("길이{}인 구간의 MAPE:{:.3f}".format(end-start, MAPEval(result[start:end], realval[start:end])))
길이5인 구간의 MAPE:1.891
길이10인 구간의 MAPE:3.546
길이20인 구간의 MAPE:7.241
길이30인 구간의 MAPE:11.775
길이50인 구간의 MAPE:15.310
결측 구간의 MAPE를 계산해서 정확히 어느정도 수치로 정확한지 계산해 보았다.
그 결과 결측된 길이가 길어질 수록 점점 정확도가 떨어지는 것을 확인할 수 있었다.
Conclusion
시계열 데이터의 결측치 대체 모델인 BRITS를 코드 구현하고 결과를 확인해 보았다.
그 결과 결측 구간의 길이가 짧은때는 좋은 성능을 보여주지만 길이가 길어질 수록 점점 성능이 나빠지는 것을 확인했다.
그래프를 확인해 보면 결측치의 구간이 길어질 수록 진폭이 줄어드는 것을 확인할 수 있었다.
BRITS가 RNN기반이라서 결측치의 time stamp가 길어지면 실제 값에 대한 정보가 점점 희미해지는 것과 temporal decay factor를 사용하기 때문에 긴 길이의 결측치에 대해서는 좋은 성능을 보여주지 못하는 것으로 생각된다.
하지만 짧은 길이에 대해서는 좋은 성능을 보여주기 때문에 임의의 구간에 짧은 결측치가 다수 존재하는 데이터의 경우에는 사용하기 적합한 모델이라고 생각된다.