[인공지능 데브코스] 3주차 day5 - EDA project
12월 18일 금
어제 배웠던 EDA를 기반으로 내가 직접 데이터를 선택하고 EDA를 진행해 보았다. 체스 데이터를 선택하고 진행했다. 처음이라 그런지 생각보다 시간이 오래 걸렸고 보고 싶던 특성을 추출하지 못했던 것도 있었다. 하지만 데이터를 다루는 것이 익숙해 질 수 있는 좋은 경험을 한 것 같다.
Embarked
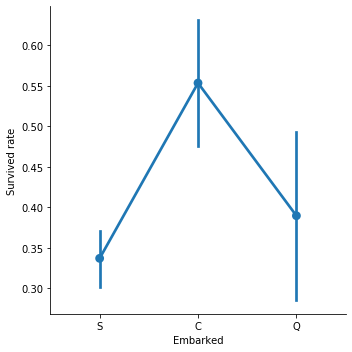
선착장 별로 생존률을 그래프로 나타내었습니다.
그 결과 선착장들의 신뢰구간이 거의 겹치지 않는 결과가 나왔고 C에서 가장 높은 생존률을 보이는 것을 확인할 수 있었습니다.
이를 통해 선착장은 생존률과 유의미한 상관관계가 있는 feature인 것을 알 수 있습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
titanic_df = pd.read_csv("./train.csv")
titanic_df.corr()
print(titanic_df[['Embarked', 'Survived']].groupby('Embarked').mean())
sns.catplot(x = 'Embarked', y = 'Survived', kind = 'point', data = titanic_df)
plt.ylabel("Survived Rate")
plt.show()
Survived
Embarked
C 0.553571
Q 0.389610
S 0.336957
Fare
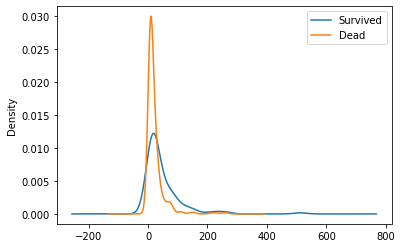
이번엔 fare별로 생존률이 어떻게 되는지 kde그래프로 나타내 보았습니다.
그 결과 확실히 낮은 가격을 지불한 사람에서 사망한 사람이 많이 나타나는 것을 확인 할 수 있습니다.
Pclass와 Fare가 보통 비례하는 경우가 많기 때문에 Pclass때와 비슷한 결과가 나온 것을 알 수 있습니다.
moves = chess_df['moves'].str.split(" ")
first_move = moves.apply(lambda x: x[:2])
first_move = pd.Series(first_move, name = 'first_move')
chess_df1 = pd.concat([chess_df, first_move], axis=1)
titanic_df[titanic_df['Survived'] == 1]['Fare'].plot(kind = 'kde')
titanic_df[titanic_df['Survived'] == 0]['Fare'].plot(kind = 'kde')
plt.legend(['Survived', 'Dead'])
plt.show()
데이터 선택
저는 Kaggle에서 Chess Game Dataset이라는 체스게임의 정보가 담겨져 있는 데이터셋을 선택하고 분석하였습니다. 이 데이터에는 Lichess.org라는 체스사이트에서의 체스 기록 20000여판의 정보가 있었습니다. 체스 게임에서 가장 중요한 것은 승리 이기 때문에 승리와 관련된 3가지의 유의미한 Feature를 찾고 분석해 보았으며 그 Feature는 아래와 같습니다.
- 흑, 백에 따른 승률
- 오프닝에 따른 승률
- rating의 차이에 따른 승률
chess_df = pd.read_csv('./games.csv')
chess_df.columns #20058 rows
Index(['id', 'rated', 'created_at', 'last_move_at', 'turns', 'victory_status',
'winner', 'increment_code', 'white_id', 'white_rating', 'black_id',
'black_rating', 'moves', 'opening_eco', 'opening_name', 'opening_ply'],
dtype='object')
흑, 백에 따른 승률
전체 승률
흔히 있는 말 중 모든 턴제 게임은 선공이 유리하다는 말이 있는데 과연 체스에서도 이러한 경향이 있을지 확인해 보았습니다.
그 결과 흑의 승률은 약 45%, 백의 승률은 약 50%로 5%가량 차이가 날 정도로 큰 차이를 보이고 있었으며 백이 이길 확률은 흑보다 5%나 높게 나온 것을 확인 할 수 있었습니다.
winrate = chess_df['winner'].value_counts() / chess_df['winner'].count() * 100
print(winrate)
sns.countplot(x = 'winner', data = chess_df)
plt.show()
white 49.860405
black 45.403330
draw 4.736265
Name: winner, dtype: float64
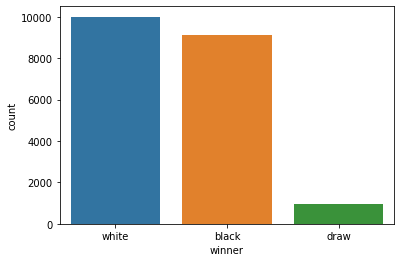
rating에 따른 승률
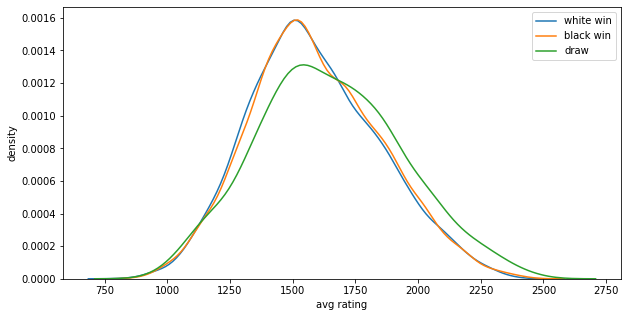
하지만 이러한 경향은 플레이어의 실력에 따라 달라질 수 있다는 생각이 들어서 rating에 따른 승률도 분석해보았습니다.
white_rating과 black_rating을 평균을 낸 avg_rating이라는 Series를 추가해 주어서 해당 게임의 평균 rating을 알 수 있도록 한후 평균 rating에 따른 승리한 색의 분포를 kdeplot을 이용하여 그려보았습니다.
그 결과 레이팅이 낮은곳에서는 미세하게 백이 높은 승률을 가지고 있었고 레이팅이 높은곳에서는 흑이 미세하게 높은 승률을 가지고 있었습니다.
그러나 두 그래프는 거의 비슷한 모양을 가지고 있는 것과 다르게 무승부에 대한 그래프는 다른 형태를 띄고 있었습니다. 그래프를 보면 높은 rating에서 확실히 많은 무승부가 일어나는 것을 알 수 있습니다.
fig, ax = plt.subplots(1,1, figsize = (10,5))
sns.kdeplot(chess_df[chess_df['winner'] == 'white']['avg_rating'], ax = ax)
sns.kdeplot(chess_df[chess_df['winner'] == 'black']['avg_rating'], ax = ax)
sns.kdeplot(chess_df[chess_df['winner'] == 'draw']['avg_rating'], ax = ax)
plt.xlabel('avg rating')
plt.ylabel('density')
plt.legend(['white win', 'black win', 'draw'])
plt.show()
이러한 경향을 좀더 자세히 분석해 보기 위해 백, 흑, 무승부가 각각 어느 rating에서 많이 일어나는지 catplot을 이용하여 분석해보았습니다.
그 결과 흑의 승리는 확실히 백의 승리보다 높은 rating에서 일어나고 있는 것을 알 수 있었으며 무승부는 확실히 실력이 있는 사람들 사이에서 많이 일어나고 있는 것을 확인 할 수 있었습니다.
sns.catplot(x = 'winner', y = 'avg_rating', kind = 'point', data = chess_df1)
plt.show()
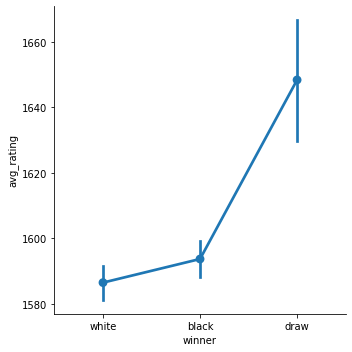
하지만 이러한 결과는 단지 흑이 이기는 경우가 높은 rating에서 많이 일어난다는 뜻이지 높은 rating에서 흑이 높은 승률을 가지고 있다는 뜻은 아니기 때문에 rating구간별 직접적인 승률을 계산해 보았습니다.
분석을 위해 일단 white, black, draw라는 문자열로 정보가 주어지는 winner를 다루게 쉽게하기 위해 백의 승률을 나타내는 숫자형 정보로 변환하였고 white는 1로 black 은 0으로 draw는 0.5로 값을 가지는 white_win이라는 새로운 series를 만들고 병합해주었습니다.
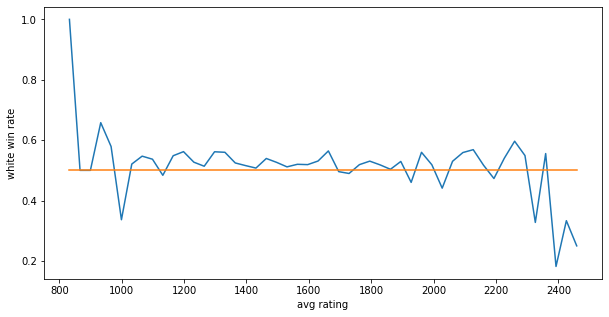
그 후 avg_rating을 50여개의 구간으로 나누고 각 구간에서의 백의 승률의 평균을 계산하여 분석해 보았습니다.
그 결과 표본의 개수가 적은 매우낮거나 높은 rating을 제외하고는 대부분 백의 승률이 50%이상 나오는 것을 알 수 있었습니다. 흑의 승률이 높은 구간은 rating이 낮은 구간보다 높은 구간에서 더 많이 일어나긴 하지만 평균적인 승률은 전체적으로 백이 더 높은 것을 확인 할 수 있었습니다.
avg_rating = (chess_df['white_rating'] + chess_df['black_rating'])/2
chess_df['avg_rating'] = avg_rating
white_win = chess_df['winner'].apply(lambda x: ((x=='white') + (x!='black'))/2)
chess_df['white_win'] = white_win
chess_df['x'] = pd.cut(chess_df['avg_rating'], 50)
result = chess_df.groupby('x')['white_win'].mean()
result = result.rename(lambda x: (x.left + x.right)/2)
plt.figure(figsize = (10,5))
plt.xlabel('avg rating')
plt.ylabel('white win rate')
plt.plot(result)
plt.plot([result.keys()[0], result.keys()[-1]], [0.5,0.5])
plt.show()
결론
전체 승률을 비교했을 때는 백의 승률이 높게 나왔으며 rating별로 승률을 확인해 봐도 백의 승률이 평균적으로 더 높다는 것을 알 수 있었습니다. 하지만 rating이 높아질 수록 흑이 이기는 경우가 점점 많아지며 아주 높은 rating에서는 거의 비슷한 수치를 가지고 있다는 것을 알 수 있었습니다. 추가로 무승부는 실력이 높은 사람들에게 주로 일어났습니다.
결론은 체스에서는 백이 유리한것은 맞지만 실력이 올라갈수록 그 차이가 점점 줄어든다 라고 정리해 볼 수 있을 것 같습니다.
오프닝에 따른 승률
오프닝 코드에 따른 승률
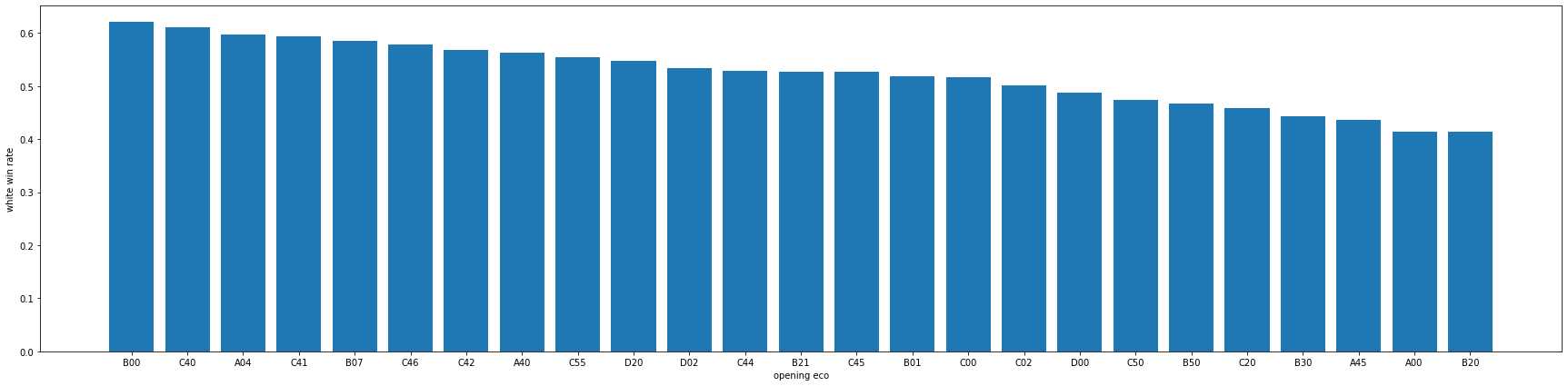
데이터에는 오프닝을 코드로 분류해놓은 opening_eco 라는 정보가 있었는데 이에 따라 흑, 백의 승률이 어떻게 달라지는지 분석해 보았습니다.
그러나 오프닝 코드의 종류는 300여가지가 넘어가서 분석하기 어렵고 한두번만 쓰인 코드들은 승률이 1, 0과같은 극단적인 값이 나오기 때문에 빈도가 200회 이상 넘어가는 오프닝만 추출해서 백의 승률을 분석하였습니다.
그렇게 25개의 오프닝코드에서의 백의 승률을 분석한 결과 백의 승률이 가장 낮은 코드는 약 41%인 B20와 A00, 백의 승률이 가장 높은 코드는 약 62%인 B00이 나왔습니다. 이 결과로 백의 입장이라면 B00오프닝을, 흑의 입장이라면 A00오프닝을 유도하는 것이 승리할 확률을 높일 수 있다는 사실을 알 수 있었습니다.
grouped_count = chess_df[['white_win', 'opening_eco']].groupby('opening_eco').count()
grouped_sum = chess_df[['white_win', 'opening_eco']].groupby('opening_eco').sum()
grouped = grouped_sum[grouped_count>=200] / grouped_count[grouped_count >= 200]
grouped = grouped.dropna(axis = 0)
grouped = grouped.sort_values(by = 'white_win', ascending = False)
plt.figure(figsize = (30,7))
plt.ylabel("white win rate")
plt.xlabel("opening eco")
plt.bar(x = grouped['white_win'].index, height = grouped['white_win'])
plt.show()
grouped
| white_win | |
|---|---|
| opening_eco | |
| B00 | 0.620295 |
| C40 | 0.610987 |
| A04 | 0.596491 |
| C41 | 0.593343 |
| B07 | 0.585526 |
| C46 | 0.578652 |
| C42 | 0.567278 |
| A40 | 0.562298 |
| C55 | 0.554487 |
| D20 | 0.547393 |
| D02 | 0.533410 |
| C44 | 0.528000 |
| B21 | 0.527426 |
| C45 | 0.526408 |
| B01 | 0.518156 |
| C00 | 0.516588 |
| C02 | 0.501805 |
| D00 | 0.487145 |
| C50 | 0.473978 |
| B50 | 0.466814 |
| C20 | 0.458519 |
| B30 | 0.442731 |
| A45 | 0.436508 |
| A00 | 0.414598 |
| B20 | 0.414462 |
첫 수에 따른 승률
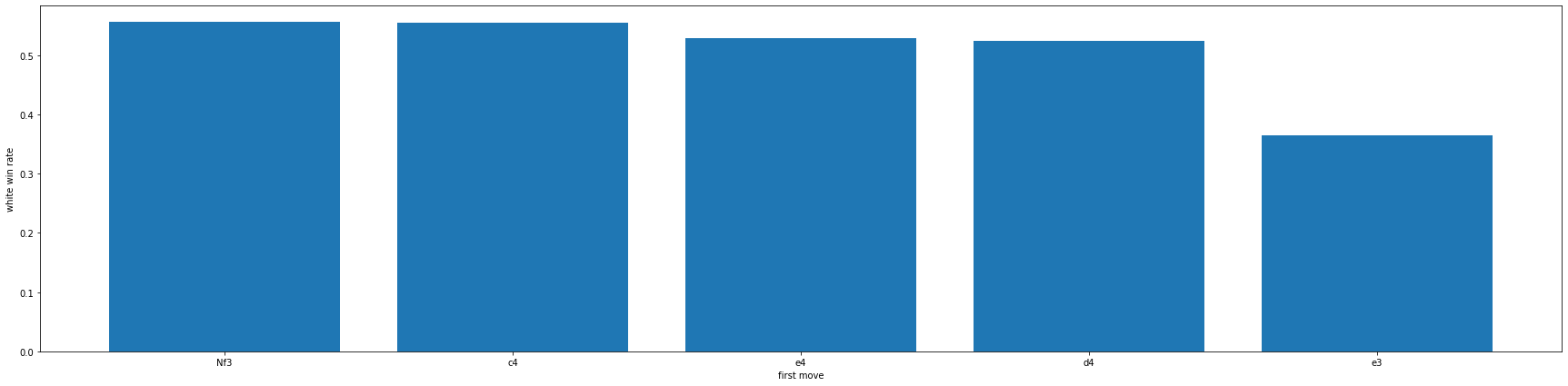
위와 같이 분석을 해보았지만 오프닝 코드가 뭔지 잘 모르고 오프닝을 유도하는 것은 상대도 원하는 대로 움직여줘야하기 때문에 힘든 일이라 생각하여 첫 수에 대해서만 승률을 분석해 보았습니다.
일단 체스경기의 전체 기보가 담긴 moves에서 첫 수의 대한 정보만 추출해서 first_move라는 새로운 series를 만들고 병합해주었습니다. 그리고 위에서 만들었던 white_win을 그대로 사용하여 첫수에 따른 승률도 분석하였습니다.
위와 마찬가지로 개수가 200개 이상되는 첫수만 뽑아내었으며 그 결과 5개의 첫수에 대한 승률을 알 수 있었고 백의 입장에서 봤을 때 가장 낮은 승률은 약 36%인 e3로 킹앞의 폰을 두칸 전진하는 경우가 가장 승률이 좋지 않은 결과가 나왔고 가장 높은 승률은 약 56%인 Nf3로 오른쪽 나이트를 왼쪽위로 이동하는 것이 가장 좋은 승률을 나타내는 것을 알 수 있었습니다. c4또한 Nf3와 매우 비슷한 승률로 비숍열의 폰을 두 칸 전진하는 수도 좋은 승률을 가지고 있었습니다.
moves = chess_df['moves'].str.split(" ")
first_move = moves.apply(lambda x: x[:1])
first_move = first_move.apply(lambda x: "".join(x))
chess_df['first_move'] = first_move
grouped_count = chess_df[['white_win', 'first_move']].groupby('first_move').count()
grouped_sum = chess_df[['white_win', 'first_move']].groupby('first_move').sum()
grouped = grouped_sum[grouped_count>=200] / grouped_count[grouped_count >= 200]
grouped = grouped.dropna(axis = 0)
grouped = grouped.sort_values(by = 'white_win', ascending = False)
plt.figure(figsize = (30,7))
plt.ylabel("white win rate")
plt.xlabel("first move")
plt.bar(x = grouped['white_win'].index, height = grouped['white_win'])
plt.show()
grouped
| white_win | |
|---|---|
| first_move | |
| Nf3 | 0.555862 |
| c4 | 0.554469 |
| e4 | 0.528576 |
| d4 | 0.523773 |
| e3 | 0.364183 |
첫 두 수에 대한 승률
이렇게만 분석하면 흑이 슬퍼할 수도 있으므로 같은 방법으로 이번에 흑이 대응하는 수까지 포함하여 두 수에 대한 정보를 같은 방법으로 분석하였습니다.
그 결과 14개의 플레이에 대한 승률을 분석해 볼수 있었고 가장 승률이 낮은 수는 35%의 승률인 e3e5, 가장 승률이 높은 수는 63%로 e4Nc6이 나온 것을 알 수 있었습니다.
이로 인해 흑은 백이 e3을 해줬다면 웃으면서 e5로 맞대응을 하면 이길확률은 65%로 높게 나온다는 것을 알 수 있고 백이 e4를 했을 때 Nc6으로 대응하는 것은 37%로 승률이 낮다는 사실을 인지해야 한다는 생각을 할 수 있었습니다.
만약 위에 있던 통계를 보고 빨리 적용해보고 싶은 백이 Nf3으로 시작했다면 d5로대응하여 56%의 승률을 그나마 52%로 떨어뜨릴 수 있다는 것을 알 수 있었습니다.
이러한 첫두수와 오프닝코드가 연관이 있지 않을까 싶어 오프닝코드를 찾아본 결과 e3e5는 백에서 승률이 가장 좋지 않았던 A00오프닝의 시작 기보였고 e4Nc6는 백에서 승률이 가장 높았던 B00의 시작 기보였습니다.
별 생각없이 그냥 분석만 해봤는데 오프닝코드와 첫 두수 의 대한 승률의 최대와 최소가 동일한 행동이라는 사실이 매우 놀라웠고 오프닝과 첫 수가 승률에 대해서 같은 상관관계를 가지고 있는 것을 알 수 있었습니다.
moves = chess_df['moves'].str.split(" ")
second_move = moves.apply(lambda x: x[:2])
second_move = second_move.apply(lambda x: "".join(x))
chess_df['second_move'] = second_move
grouped_count = chess_df[['white_win', 'second_move']].groupby('second_move').count()
grouped_sum = chess_df[['white_win', 'second_move']].groupby('second_move').sum()
grouped = grouped_sum[grouped_count>=200] / grouped_count[grouped_count >= 200]
grouped = grouped.dropna(axis = 0)
grouped = grouped.sort_values(by = 'white_win', ascending = False)
plt.figure(figsize = (30,7))
plt.ylabel("white win rate")
plt.xlabel("second move")
plt.bar(x = grouped['white_win'].index, height = grouped['white_win'])
plt.show()
grouped
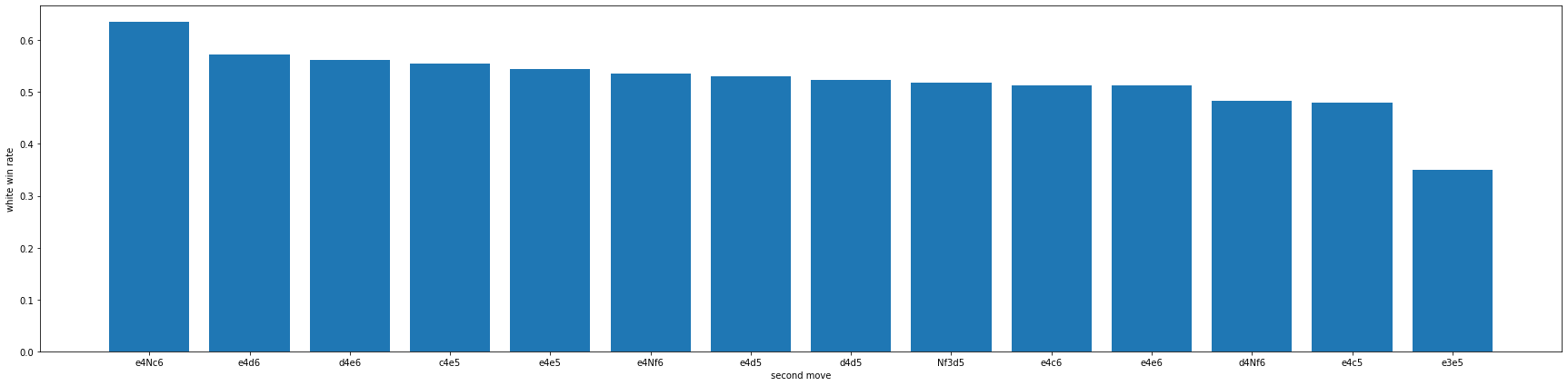
| white_win | |
|---|---|
| second_move | |
| e4Nc6 | 0.634703 |
| e4d6 | 0.572464 |
| d4e6 | 0.562356 |
| c4e5 | 0.555556 |
| e4e5 | 0.544535 |
| e4Nf6 | 0.534884 |
| e4d5 | 0.530284 |
| d4d5 | 0.524027 |
| Nf3d5 | 0.517787 |
| e4c6 | 0.513489 |
| e4e6 | 0.512953 |
| d4Nf6 | 0.482865 |
| e4c5 | 0.480046 |
| e3e5 | 0.350000 |
결론
확실히 백의 첫수는 경우의 수가 적어서 최적의 수를 분석하기 쉬웠지만 그의 따른 흑의 대응은 경우의수가 많아서 최적의 수를 찾기가 힘들었습니다. 이는 처음에 분석했던 백이 승률이 높은 이유와 관련이 있어보입니다.
결론은 백일때는 NFc3혹은 c4로 시작하고 흑입장에서 백이 e3을 했다면 e5로 대응하자라고 요약해 볼 수 있을 것 같습니다.
물론 그저 통계이기때문에 맹신할 수는 없을 것 같습니다.
rating 차이에 따른 승률
과연 이 체스 사이트의 rating이 실력을 잘 대변해 주는지 확인하기 위 각 매치에서 각 선수의 rating차이와 승리자가 어떤 관계를 가지고 있는지 분석해 보았습니다.
백의 rating에서 흑의 rating을 뺀 값을 새로운 열로 추가시켜주었고 백의 승리여부에 따라 분석해 보았습니다.
그 결과 차이가 클수록 백이 잘이기고 비슷하면 비기고 작을수록 흑이 잘이기는 정상적인 결과를 얻어낼 수 있었습니다.
rate_diff = chess_df['white_rating'] - chess_df['black_rating']
chess_df['rate_diff'] = rate_diff
sns.catplot(x = 'white_win', y = 'rate_diff', kind = 'point', data = chess_df)
plt.show()
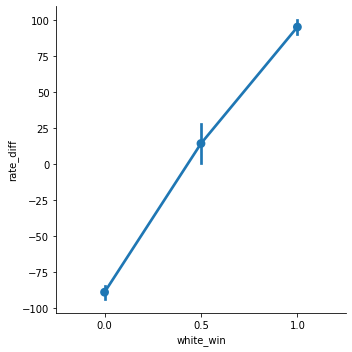
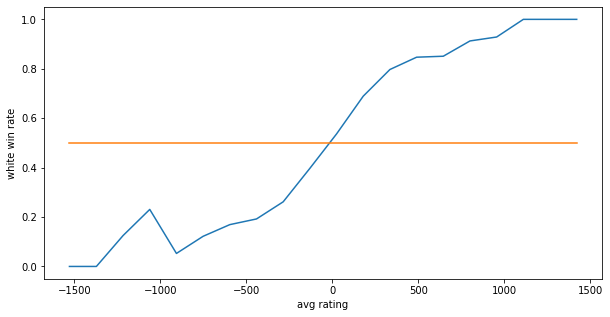
추가로 rating의 차이에 따른 직접적인 승률을 알아보고자 rate_diff를 20개의 구간으로 나누고 각 구간별 평균 승률을 계산해보았습니다.
그 결과 거의 선형적인 그래프가 나왔으며 rating차이가 크면 이길 확률이 높아지는 것을 직접적으로 확인할 수 있었습니다.
추가로 rating의 차이가 커질수록 승률은 완만하게 증가하므로 rating의 차이가 낮은 구간에서 승률의 변화가 크게 일어난다는 것도 알 수 있었습니다.
rating이 1000이상 차이나는 경우의 찌그러진 모양은 매칭의 특성상 표본이 적기때문에 무시해도 될 것같습니다.
chess_df['x'] = pd.cut(chess_df['rate_diff'], 20)
result = chess_df.groupby('x')['white_win'].mean()
result = result.rename(lambda x: (x.left + x.right)/2)
plt.figure(figsize = (10,5))
plt.xlabel('rating diff')
plt.ylabel('white win rate')
plt.plot(result)
plt.plot([result.keys()[0], result.keys()[-1]], [0.5,0.5])
plt.show()
결론
Lichess.org의 rating은 실제 실력과 밀접한 관련이 있으며 믿을만하다.
rating이 400정도만 차이나도 승률은 크게 올라가며 그 이후로는 완만하게 올라간다.